Linux内核及内核编程
由于Linux驱动编程本质属于Linux内核编程,因此有必要掌握Linux内核及内核编程的基础知识。
3.1-3.2节讲解Linux内核的演变及Linux2.6内核的特点。
3.3节分析了Linux内核源代码目录结构和Linux内核的组成部分及其关系,并对Linux的用户空间和内核空间进行了讲解。
3.4节讲解了Linux2.6内核的编译及内核引导过程。另外,还描述了在Linux内核中新增程序的方法,驱动工程师编写的设备驱动也应该以此方式被添加。
3.5节讲解了Linux下C编程的命名习惯以及Linux所使用的GNU C针对标准C的扩展语法。
3.1 Linux内核的发展与演变
Linux操作系统诞生于1991年10月5日(第一次正式向外公布的时间)。Linux操作系统的诞生、发展和成长过程依赖于UNIX操作系统、MINIX操作系统、GNU计划、POSIX标准和Internet。
1. UNIX操作系统
UNIX操作系统是美国贝尔实验室的Ken.Thompson和Dennis.RitChie于1969年在DEC PDP-7小型计算机上开发的一个分时操作系统。Linux操作系统可看作UNIX操作系统的一个克隆版本。
2. Minix操作系统
Minix操作系统也是UNIX操作系统的一种克隆系统,它于1987年由著名计算机教授Andrew S.Tanenbaum开发完成。开放源代码Minix操作系统的出现在全世界的大学中刮起了学习操作系统的旋风。Linux操作系统刚开始就是参照Minix操作系统开发进行的。
3. GNU计划
GNU计划和自由基金会(FSF)是由Richard M.Stallman于1984年创办的,GNU是“GNU is Not UNIX”的递归缩写。到20世纪90年代初,GNU项目已经开发出许多高质量的免费软件,其中包括Emacs编辑系统、Bash Shell程序、GCC系列编译程序、GDB调试程序等。这些软件为Linux操作系统的开发创造了一个合适的环境,是Linux操作系统诞生的基础之一。没有GNU软件环境,Linux操作系统将寸步难行。因此,严格而言,Linux严格被称为GNU/Linux操作系统。
4. POSIX标准
POSIX(Portable Operating System Interface for Computing Systems,可移植的操作系统接口)是由IEEE和ISO/IEC开发的一组标准。该标准基于现有的UNIX实践和经验完成,描述了操作系统的调用服务接口,用于保证编制的应用程序可以在源代码一级上在多种操作系统上移植。该标准在推动Linux操作系统朝着正规化方向发展起着重要的作用,是Linux前进的灯塔。
5. Internet
如果没有Internet,没有遍布全世界的Linux爱好者的无私奉献,那么Linux操作系统就不可能发展到现在的水平。
Linux操作系统重要版本的变迁历史及各版本的主要特点如下表所示。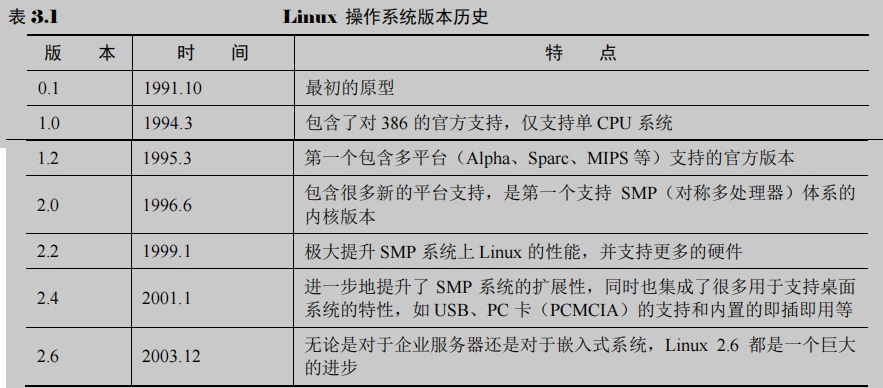
从上表可以看出,Linux操作系统一直朝着支持更多的CPU、硬件体系结构和外部设备,支持更广泛领域的应用,提供更好的性能方向发展。
除了Linux内核本身可提供免费下载之外,一些厂商封装了Linux内核和大量有用的软件包,制定了相应的Linux发行版,如Red Hat Linux、Turbo Linux、Debian、SuSe,国内的RedFlag和Xteam等。
针对嵌入式系统的应用,一些改进内核的Linux操作系统被开发出来,如改进实时性的Hard Hat Linux和RTLinux,支持不含MMU CPU的McLinux,面向数字相机和MP3等微型嵌入式设备的ThinLinux,以及颇有商业背景的MontaVista等。
3.2 Linux2.6内核的特点
尽管Linux2.4目前仍然被广泛应用,但是本书是基于Linux2.6内核的。从2003年12月Linux2.6.0发布至今,一直还处于开发之中,并还将稳定较长一段时间。Linux2.6相对于Linux2.4有相当大的改进,主要体现在如下几个方面。
1. 新的调度器
2.6版本的Linux内核使用了新的进程调度算法,它在高负载的情况下执行得极其出色,并且当有很多处理器时也可以很好的扩展。
2. 内核抢占
在2.6版本的Linux内核中,内核任务可以被抢占,从而提高系统的实时性。这样做最主要的优势在于可以极大地增强系统的用户交互性。
3. 改进的线程模型
2.6版本的Linux内核中线程操作速度得以提高,可以处理任意数目的线程,PID最大可以到2000000000。
4. 虚拟内存的变化
从虚拟内存的角度来看,新内核融合了r-map(反向映射)技术,显著改善虚拟内存在一定程度负载下的性能。
5. 文件系统
2.6版本的Linux内核增加了对日志文件系统功能的支持,解决了2.4版本的Linux内核在这方面的不足。2.6版本的Linux内核在文件系统上的关键变化还包括对扩展属性及POSIX标准访问控制的支持。Ext2/Ext3作为大多数Linux系统缺省安装的文件系统,在2.6版本的Linux内核增加了对扩展属性的支持,可以给指定的文件在文件系统中嵌入元数据。
6. 音频
新的Linux音频体系结构ALSA(Advanced Linux Sound Architecture)取代了缺陷很多的旧的OSS(Open Sound System)。新的声音体系结构支持USB音频和MIDI设备,并支持全双工重放等功能。
7. 总线
SCSI/IDE子系统经过大幅度的重写,解决和改善了以前的一些问题。比如2.6版本的Linux内核可以直接通过IDE驱动程序来支持IDE CD/RW设备,而不必像以前那样使用一个特别的SCSI模拟驱动程序。
8. 电源管理
支持ACPI(高级电源配置管理界面,Advanced Configuration and Power Interface),用于调整CPU在不同的负载下工作于不同的时钟频率以降低功耗。
9. 联网和IPSec
2.6版本的Linux内核中加入了对IPSec的支持,删除了原来内核内置的HTTP服务器kttpd,加入了对新的NFSv4(网络文件系统)客户机/服务器的支持,并改进了对IPv6的支持。
10. 用户界面层
2.6版本的Linux内核重写了帧缓冲/控制台层,人机界面层还加入了对大多数接口设备的支持(从触摸屏到盲人用的设备和各种各样的鼠标)。
在设备驱动程序的方面,Linux2.6相对于Linux2.4也有较大的改动,这主要表现在内核API中增加了不少新功能(例如内存池)、sysfs文件系统、内核模块从.o变成.ko、驱动模块编译方式、模块使用计数、模块加载和卸载函数的定义等方面。
3.3 Linux内核的组成
3.3.1 Linux内核源代码目录结构
本书范例程序所基于的Linux2.6.15.5内核源代码压缩包“linux-2.6.15.5.tar.bz2”共38.912KB,包含如下目录。
- arch:包含和硬件体系结构相关的代码,每种平台占一个相应的目录,如i386、ARM、PowerPC、MIPS等。
- block:块设备驱动程序I/O调度。
- crypto:常用加密和散列算法(如AES、SHA等),还有一些压缩和CRC校验算法。
- Documentation:内核各部分的通用解释和注释。
- drivers:设备驱动程序,每个不同的驱动占用一个子目录,如char、block、net、mtd、i2c等。
- fs:支持的各种文件系统,如EXT、FAT、NTFS、JFFS2等。
- include:头文件,与系统相关的头文件被放置在include/linux子目录下。
- init:内核初始化代码。
- ipc:进程间通信的代码。
- kernel:内核的最核心部分,包括进程调度、定时器等,而和平台相关的一部分代码放在arch/*/kernel目录下。
- lib:库文件代码。
- mm:内存管理代码,和平台相关的一部分代码放在arch/*/mm目录下。
- net:网络相关代码,实现了各种常见的网络协议。
- scripts:包含用于配置内核的脚本文件。
- security:主要包含SELinux模块。
- sound:ALSA、OSS音频设备的驱动核心代码和常用设备驱动。
- usr:实现了用于打包和压缩的cpio等。
3.3.2 Linux内核的组成部分
如下图所示,Linux内核主要由进程调度(SCHED)、内存管理(MM)、虚拟文件系统(VFS)、网络接口(NET)和进程间通信(IPC)等5个子系统组成。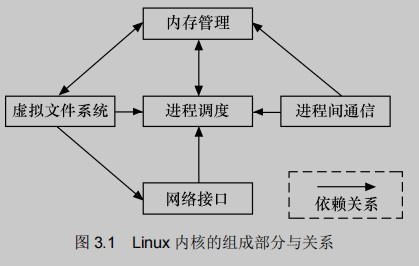
1. 进程调度
精度调度控制系统中的多个进程对CPU的访问使得多个进程能在CPU中围观串行,宏观并行地执行。进程调度处于系统中的中心位置,内核中其他的子系统都依赖它,因为每个子系统都需要挂起或恢复进程。
如下图所示,Linux的进程在几个状态间进行切换。在设备驱动编程中,当请求的资源不能得到满足时,驱动一般会调度其他进程执行,并使驱动对应的进程进入睡眠状态,直到它请求的资源被释放,才会被唤醒而进入就绪状态。睡眠分为可被打断的睡眠和不可被打断的睡眠,两者的区别在于可被打断的睡眠在收到信号的时候才会醒来。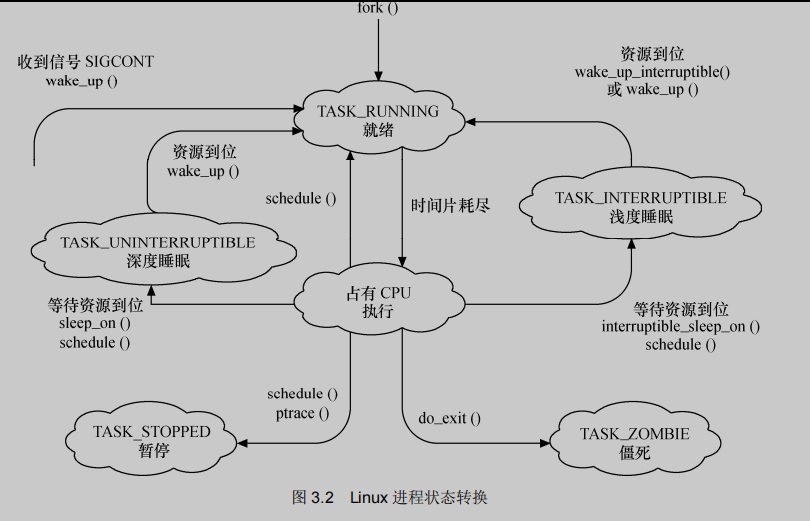
在设备驱动编程中,当请求的资源不能得到满足时,驱动一般会调度其他进程执行,其对应的进程进入睡眠状态,直到它请求的资源被释放,才会被唤醒而进入就绪状态。
设备驱动中,如果需要几个并发执行的任务,可以启动内核线程,启动内核线程的函数为:
1 | int kernel_thread(int (*fn)(void *),void *arg,unsigned long flags); |
2. 内存管理
内存管理的主要作用是控制多个进程安全地共享主内存区域。当CPU提供内存管理单元(MMU)时,Linux内存管理完成为每个进程进行虚拟内存到物理内存的转换。Linux2.6引入了对无MMU CPU的支持。
如下图所示,一般而言,Linux的每个进程享有4GB的内存空间,0-3GB属于用户空间,3-4GB属于内核空间,内核空间对常规内存、I/O设备内存以及高端内存存在不同的处理方式。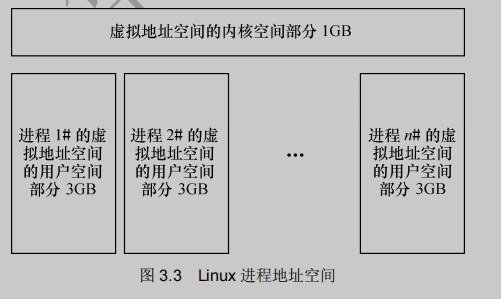
3. 虚拟文件系统
如下图所示,Linux虚拟文件系统(VFS)隐藏了各种硬件的具体细节,为所有的设备提供了统一的接口。而且,它独立于各个具体的文件系统,是对各种文件系统的一个抽象,它使用超级块super block存放文件系统相关信息,使用索引节点inode存放文件的物理信息,使用目录项dentry存放文件的逻辑信息。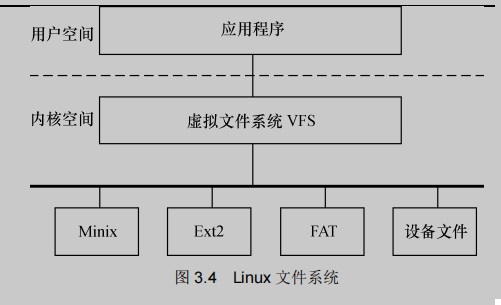
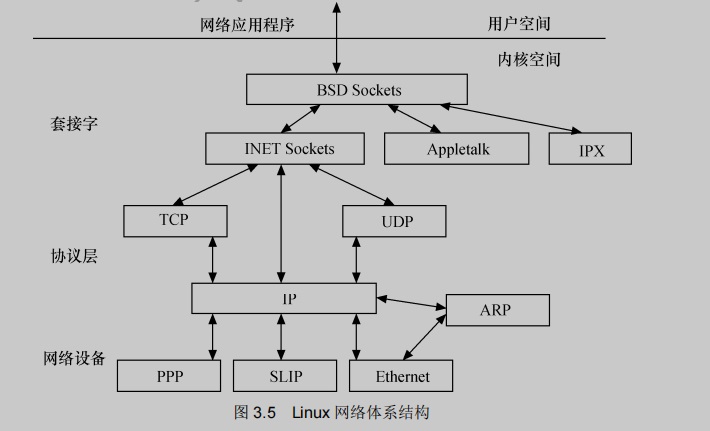
4. 网络接口
网络接口提供了对各种网络的标准的存取和各种网络硬件的支持。网络接口可分为网络协议和网络驱动程序,网络协议部分负责实现每一种可能的网络传输协议,网络设备驱动程序负责与硬件设备进行通信,每一种可能的硬件设备都由相应的设备驱动程序。
5. 进程通信
Linux支持进程间的多种通信机制,包括信号量、共享内存、管道等,这些机制可协助多个进程、多资源的互斥访问、进程间的同步和消息传递。
Linux内核的5个组成部分之间的依赖关系如下:
进程调度与内存管理之间的关系:两个子系统互相依赖。在多道程序环境下,必须为程序创建进程,而创建进程的第一件事情就是将程序和数据装入内存。- 进程间通信与内存管理的关系:进程间通信子系统要依赖内存管理支持共享内存通信机制,这种机制允许两个进程除了拥有自己的私有空间,还可以存取共同的内存区域。
- 虚拟文件系统与网络接口之间的关系:虚拟文件系统利用网络接口支持网络文件系统(NFS),也利用内存管理支持RAMDISK设备。
- 内存管理和虚拟文件系统之间的关系:内存管理利用虚拟文件系统支持交换,交换进程(swapd)定期由调度程序调度,这也是内存管理依赖于进程调度的唯一原因。当一个进程存取的内存映射被换出时,内存管理向文件系统发出请求,同时,挂起当前正在运行的进程。
除了这些依赖关系外,内核中的所有子系统还要依赖于一些共同的资源。这些资源包括所有子系统都用到的例程,如分配和释放内存空间的函数、打印警告或错误信息的函数及系统提供的调试例程等。
3.3.3 Linux内核空间与用户空间
现代CPU内部往往实现了不同的操作模式(级别)。
例如,ARM处理器有以下7种工作模式。
- 用户模式(usr):大多数的应用程序运行在用户模式下,当处理器运行在用户模式下,某些被保护的系统资源是不能被访问的。
- 快速中断模式(fiq):用于高速数据传输或通道处理。
- 外部中断模式(irq):用于通用的中断处理。
- 管理模式(svc):操作系统使用的保护模式。
- 数据访问终止模式(abt):当数据或指令预取终止时进入该模式,可用于虚拟存储及存储保护。
- 系统模式(sys):运行具有特权的操作系统任务。
- 未定义指令中止模式(und):当未定义的指令执行时进入该模式,可用于支持硬件协处理器的软件仿真。
又如,X86处理器包含4个不同的特权级,称为Ring0-Ring3。Ring0下,可以执行特权级指令,对任何I/O设备都有访问权等,而Ring3则有很多操作限制。
Linux系统充分利用CPU的这一硬件特性,但它只使用了两级。在Linux系统中,内核可进行任何操作,而应用程序则被禁止对硬件的直接访问和对内存的未授权访问。例如,若使用X86处理器,则用户代码运行在特权级3,而系统内核代码则运行在特权级0。
内核空间和用户空间这两个名词被用来区分程序执行的这两种不同状态,它们使用不同的地址空间。Linux系统只能通过系统调用和硬件中断完成从用户空间到内核空间的控制转移。
3.4 Linux内核的编译及加载
3.4.1 Linux内核的编译
Linux驱动工程师需要牢固地掌握Linux内核的编译方法以为嵌入式系统构建可运行的Linux操作系统映像。
3.4.2 Kconfig和Makefile
在Linux内核中增加程序需要完成以下3项工作。
- 将编写的源代码复制到Linux内核源代码的相应目录。
- 在目录的Kconfig文件中增加新源代码对应项目的编译配置选项。
- 在目录的Makefile文件中增加对新源代码的编译条目。
1. 实例引导:S3C2410处理器的RTC与LED驱动配置
在讲解Kconfig和Makefile的语法之前,我们先利用两个简单的实例引导读者建立初步的认识。
首先,在linux-2.6.15.5/drivers/char目录中包含了S3C2410处理器的RTC设备驱动源代码s3c2410-rtc.c。
而在该目录的Kconfig文件中包含S3C2410_RTC的配置项目:
1 | config S3C2410_RTC |
上述Kconfig文件的这段脚本意味着只有在ARCH_S3C2410项目被配置的情况下,才会出现S3C2410_RTC配置项目,这个配置项目为布尔型(要么编译进入内核,要么不编译,选项为“Y”或“N”),菜单上显示的字符串为“S3C2410 RTC Driver”,“help”后面的内容帮助信息。下图所示为S3C2410_RTC菜单以及其help在运行make menuconfig时的情况。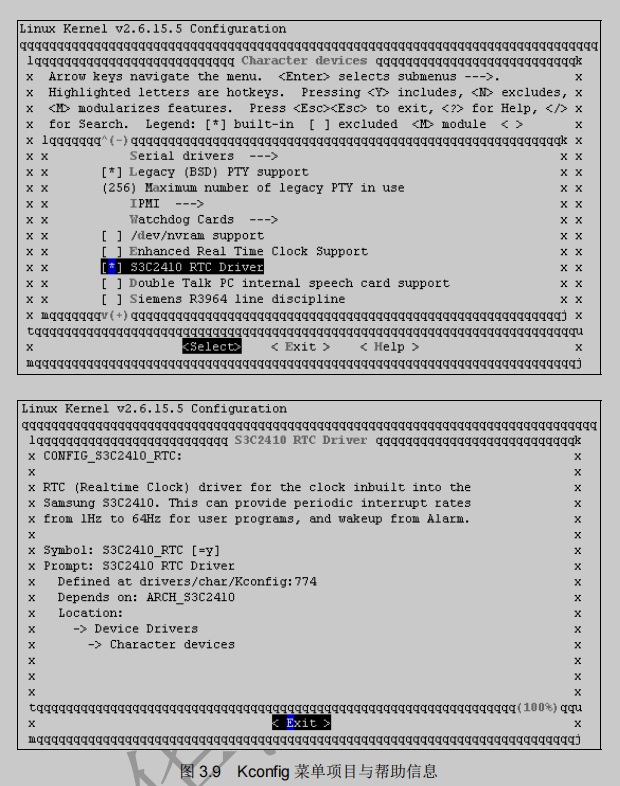
除了布尔型的配置项目外,还存在一种三态型(tristate)配置选项,它意味着要么编译入内核,要么编译为内核模块,要么不编译,选项为“Y”、“M”或“N”。
在目录的Makefile中关于S3C2410_RTC的编译脚本为:
1 | obj-$(CONFIG_S3C2410_RTC) += s3c2410-rtc.o |
上述脚本意味着如果S3C2410_RTC配置选项被选择为“Y”或“M”,即obj-$(CONFIG_S3C2410_RTC)等同于obj-y或obj-m时,则编译s3c2410-rtc.c,选“Y”的情况直接会将生成的目标代码直接连接到内核,为“M”的情况则会生成模块s3c2410-rtc.ko(由于S3C2410_RTC为布尔型,实际不会为“M”);如果S3C2410_RTC配置选项被选择为“N”,即obj-$(CONFIG_S3C2410_RTC)等同于obj-n,则不编译s3c2410-rtc.c。
一般而言,驱动工程师在内核源代码的drivers目录的相应子目录中增加新设备驱动的源代码,并增加或修改Kconfig配置脚本和Makefile脚本,完全按照上述过程执行即可。
再如,我们为S3C2410的LED编写了驱动,源代码为s3c2410-led.c。为使内核能支持对该模块的编译配置,我们应进行如下3项处理。
- 将编写的s3c2410-led.c源代码复制到linux-2.6.15.5/drivers/char目录。
- 在目录的Kconfig文件中增加LED的编译配置选项,如下所示:
1
2
3
4
5config S3C2410_LED
bool "S3C2410 LED Driver"
depends on ARCH_S3C2410
help
LED driver for the Samsung S3C2410 - 在目录的Makefile文件中增加对s3c2410-led.c源代码的编译,如下所示:
1
obj-$(CONFIG_S3C2410_LED) += s3c2410-led.o
2. Makefile
下面我们对内核源代码各级子目录中的kbuild Makefile进行介绍,这部分是内核模块或设备驱动的开发者最常接触到的。
kbuild Makefile的语法包括如下几个方面。
- 目标定义。
目标定义用来定义哪些内容要作为模块编译,哪些要编译并连接进内核。
例如:表示要由foo.c或者foo.s文件编译得到foo.o并连接进内核,而obj-m则表示该文件要作为模块编译。除了y、m以外的obj-x形式的目标都不会被编译。1
obj-y += foo.o
而更常见的做法是根据.config文件的CONFIG_变量来决定文件的编译方式,如下所示:除了obj-形式的目标以外,还有lib-y library库、hostprogs-y主机程序等目标,但是基本都应用在特定的目录和场合下。1
2obj-$(CONFIG_ISDN) += isdn.o
obj-$(CONFIG_ISDN_PPP_BSDCOMP) += isdn_bsdcomp.o - 多文件模块的定义
如果一个模块由多个文件组成,这时候应采用模块名加-objs后缀或者-y后缀的形式来定义模块的组成文件。如下面的例子所示:模块的名字为ext2,由balloc.o和bitmap.o两个目标文件最终连接生成ext2.o直至ext2.ko文件,是否包括xattr.o取决于内核配置文件的配置情况。如果CONFIG_EXT2_FS的值是y也没有关系,在此过程中生成的ext2.o将被连接进build-in.o最终连接进内核。这里需要注意的一点是,该kbuild Makefile所在的目录中不能再包含和模块名相同的源文件如ext2.c/ext2.s。1
2
3obj-$(CONFIG_EXT2_FS) += ext2.o
ext2-y := balloc.o bitmap.o
ext2-$(CONFIG_EXT2_FS_XATTR) += xattr.o
或者写成如-objs的形式:1
2obj-$(CONFIG_ISDN) += isdn.o
isdn-objs := isdn_net_lib.o isdn_v110.o isdn_common.o - 目录层次的迭代。
示例:当CONFIG_EXT2_FS的值为y或m时,kbuild将会把ext2目录列入向下迭代的目标中,具体ext2目录下的文件是要作为模块编译还是链入内核由ext2目录下的Makefile文件的内容决定。1
obj-$(CONFIG_EXT2_FS) += ext2/
3. Kconfig
内核配置脚本文件的语法也比较简单,主要包括以下几个方面。
- 菜单入口。
大多数的内核配置选项都对应Kconfig中的一个菜单入口,如下所示:config关键字定义新的配置选项,之后的几行定义了该配置选项的属性。配置选项的属性包括类型、数据范围、输入提示、依赖关系(及反向依赖关系)、帮助信息和默认值等。1
2
3
4
5config MODVERSIONS
bool "Set version infomation on all module symbols"
depends on MODULES
help
Usually,modules have to be recompile whenever you switch to a new kernel. ...
每个配置选项都必须指定类型,类型包括bool、tristate、string、hex和int,其中tristate和string是两种基本的类型,其他类型都基于这两种基本类型。类型定义后可以紧跟输入提示,下面的两段脚本是等价的。
脚本1:脚本2:1
bool "Networking support"
输入提示的一般格式如下所示:1
2bool
prompt "Networking support"其中可选的if用来表示该提示的依赖关系。1
prompt <prompt> [if <expr>]
默认值的格式如下所示:一个配置选项可以存在任意多个默认值,这种情况下,只有第一个被定义的值是可用的。如果用户不设置对应的选项,配置选项的值就是默认值。1
default <expr> [if <expr>]
依赖关系的格式如下所示:如果定义了多个依赖关系,它们之间用“&&”间隔。依赖关系也可以应用到该菜单中所有的其他选项中(这些选项同样可接受if表达式),下面的两段脚本是等价的。1
depends on (或者requires) <expr>
脚本1:脚本2:1
2bool "foo" if BAR
default y if BAR反向依赖关系的格式如下所示:1
2
3depends on BAR
bool "foo"
default ydepends能限定一个symbol的上限,即如果A依赖于B,则在B被配置为“Y”的情况下,A可以为“Y”、“M”和“N”;在B被配置为“M”的情况下,A可以被配置为“M”或“N”;B在被配置为“N”的情况下,A只能为“N”。1
select <symbol> [if <expr>]
select能限定一个symbol的下限,若A反向依赖于B,则A的配置值会高于或等于B(正好与depends相反)。如果symbol 反向依赖于多个对象,则它的下限是这些对象的最大值。
kbuild Makefile中的expr(表达式)定义如下所示:也就是说expr由symbol、两个symbol相等、两个symbol不等以及expr的赋值、非、与或运算构成。而symbol分为两类,一类是由菜单入口定义配置选项定义的非常数symbol,另一类是作为expr组成部分的常数symbol。1
2
3
4
5
6
7<expr> ::= <symbol>
<symbol> '=' <symbol>
<symbol> '!=' <symbol>
'(' <expr> ')'
'!' <expr>
<expr> '&&' <expr>
<expr> '||' <expr>
数据范围的格式如下:为int和hex类型的选项设置可以接受的输入值范围,用户只能输入大于等于第一个symbol,小于等于第二个symbol的值。1
range <symbol> <symbol> [if <expr>]
帮助信息的格式如下:帮助信息完全靠文本缩进识别结束。1
2
3
4help (或---help---)
开始
...
结束
menuconfig关键字的作用与config类似,但它在config的基础上要求所有的子选项作为独立的行显示。 - 菜单结构。
菜单入口在菜单树结构中的位置可由两种方法决定。第一种方式如下所示:所有处于“menu”和“endmenu”之间的菜单入口都会成为“Network device support”的子菜单。而且,所有子菜单选项都会继承父菜单的依赖关系,比如,“Network device support”对“NET”的依赖被加到了配置选项NETDEVICES的依赖列表中。1
2
3
4
5menu "Network device support"
depends on NET
config NETDEVICES
...
endmenu
另一种方式是通过分析依赖关系生成菜单结构。如果菜单选项在一定程度上依赖于前面的选项,它就能成为该选项的子菜单。如果父选项为“N”,则子选项不可见;如果父选项为“Y”或者“M”,则子选项可见。例如:MODVERSIONS直接依赖MODULES,如果MODULES不为“N”,该选项才可见。1
2
3
4
5
6
7
8
9config MODULES
bool "Enable loadable module support"
config MODVERSIONS
bool "Set version information on all module symbols"
depends on MODULES
commet "module support disabled"
depends on !MODULES
除此之外,Kconfig中还可能使用“choices … endchoice”、“comment”、“if…endif”这样的语法结构。其中“choices … endchoice”的结构如下所示:它定义一个选择群,其接受的选项(choice options)可以是前面描述的任何属性。在一个硬件有多个驱动的情况下使用,使用选择可以实现最终只有一个驱动被编译进内核或模块。选择群还可以接受的另一个选项是“optional”,这样菜单入口就被设置为“N”,没有被选中。1
2
3
4choice
<choice option>
<choice block>
endchoice
4. 应用实例:在内核中新增驱动代码目录和子目录
下面讲解一个综合实例,假设我们要在内核源代码drivers目录下为ARM体系结构新增如下用于test driver的树形目录:
1 | |--test |
在内核中增加目录和子目录,我们需为相应的新增目录创建Kconfig和Makefile文件,而新增目录的父目录中的Kconfig和Makefile文件也需要修改,以便新增的Kconfig和Makefile文件能被引用。
在新增的test目录下,应该包含如下Kconfig文件:
1 | # |
由于TEST Driver对于内核来说是新的功能,所以首先需要创建一个菜单TEST Driver;然后显示“TEST support”,等待用户选择;接下来判断用户是否选择了TEST Driver,如果是(CONFIG_TEST=y),则进一步显示子功能:用户接口与CPU功能支持;由于用户接口功能可以被编译成内核模块,所以这里的询问语句使用了tristate。
为了使这个Kconfig文件能起作用,需要修改arch/arm/Kconfig文件,增加以下内容:
1 | source "drivers/test/Kconfig" |
脚本中的source意味着引用新的Kconfig文件。
在新增的test目录下,应该包含如下Makefile文件:
1 | # drivers/test/Makefile |
该脚本根据配置变量的取值构建obj-*列表。由于test目录中包含一个子目录cpu,当CONFIG_TEST_CPU=y时,需要将cpu目录加入列表。
test目录中的cpu子目录也需包含如下的Makefile文件:
1 | # drivers/test/test/Makefile |
为了使得整个test目录能够被编译命令作用到,test目录父目录中的Makefile文件也需新增如下脚本:
1 | obj-$(CONFIG_TEST) += test/ |
在drivers/Makefile中加入obj-$(CONFIG_TEST) += test/,使得用户在进行内核编译时能够进入test目录。
增加了Kconfig和Makefile文件之后的新的test树形目录如下所示:
1 | |--test |
3.4.3 Linux内核的引导
1. 引导过程概述
引导Linux内核的过程包括很多阶段,这里将以引导X86 PC为例来进行讲解。引导X86 PC上的Linux内核的过程和引导嵌入式系统上的Linux内核的过程基本类似。不过在X86 PC上有一个BIOS(基本输入/输出系统)转移到Bootloader的过程,如下图所示,而嵌入式系统往往复位后就直接运行Bootloader。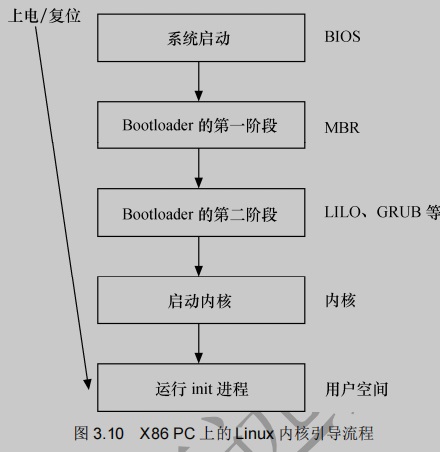
上图给出了X86 PC上从上电/复位到运行Linux用户空间初始进程的流程。在进入与Linux相关代码之前,会经历如下阶段。
- 当系统上电或复位时,CPU会将PC指针赋值为一个特定的地址0XFFFF0,并执行该地址处的指令。在PC中,该地址位于BIOS中,它保存在主板上的ROM或Flash中。
- BIOS运行时按照CMOS的设置定义的启动设备顺序来搜索处于活动状态,并且可以引导的设备。若从硬盘启动,BIOS会将硬盘MBR(主引导记录)中的内容加载到RAM。MBR是一个512字节大小的扇区,位于磁盘上的第一个扇区中(0道0柱面1扇区)。当MBR被加载到RAM中之后,BIOS就会将控制权交给MBR。
- 主引导加载区程序查找并加载引导加载程序。它在分区表中查找活动区,当找到一个活动分区时,扫描分区表中的其他分区,以确保它们都不是活动的。当这个过程验证完成之后,就将活动分区的引导记录从这个设备中读入RAM中并执行它。
- 次引导加载程序加载Linux内核和可选的初始RAM磁盘,将控制权交给Linux内核源代码。
- 运行被加载的内核,并启动用户空间程序。
2. Bootloader
嵌入式系统中Linux内核的引导过程与之类似,但一般更加简洁。不论具体以怎样的方式实现,只要具备如下特征就可以称其为Bootloader。
- 可以在系统上电或复位的时候以某种方式执行,这些方式包括被BIOS引导执行、直接在NOR Flash中执行、NAND Flash中的代码被MCU自动复制到内部或外部RAM执行等。
- 能将U盘、磁盘、光盘、NOR/NAND Flash、ROM、SD卡等存储介质,或将网口、串口中的操作系统加载到RAM,并把控制权交给操作系统源代码执行。
完成上述功能的Bootloader的实现方式非常多样化,甚至本身也可以是一个简化版的操作系统。著名的Linux Bootloader包括应用于PC的LILO和GRUB,应用于嵌入式系统的U-Boot、RedBoot等。
相比较于LILO,GRUB本身能理解Ext2、Ext3文件系统,因此可以在文件系统中加载Linux文件系统,而LILO只能识别“裸扇区”。
U-Boot的定位为“Universal Bootloader”,其功能比较强大,涵盖了包括PowerPC、ARM、MIPS和X86在内的绝大部分处理器架构,提供网卡、串口、Flash等外设驱动,提供必要的网络协议(BOOTP、DHCP、TFTP),能识别多种文件系统(cramfs、fat、jffs2和registerfs等),并附带了调试、脚本、引导等工具,应用十分广泛。
RedBoot是RedHat公司随eCos发布的Bootloader开源项目,除了包含U-Boot类似的强大功能外,它还包含GDB stub(插桩),因此能通过串口或网口与GDB进行通信,调试GCC产生的任何程序(包括内核)。
3. 详细分析
下面对上述流程的第5个阶段进行更详细的分析,它完成启动内核并运行用户空间的init进程的功能。当内核映像被加载到RAM之后,Bootloader的控制权被释放。内核映像并不是可直接执行的目标代码,而是一个压缩过的zImage(小内核)或bzImage(大内核,b的意思是big)。
但是,并非zImage和bzImage映像中的一切都被压缩了,映像中包含未被压缩的部分,这部分中包含解压缩程序,解压缩程序会解压缩映像中被压缩的部分。zImage和bzImage都是用gzip压缩的,它们不仅是一个压缩文件,而且在这两个文件的开头部分内嵌有gzip的解压缩代码。
如下图所示,当bzImage(用于i386)被调用时,它从/arch/i386/boot/head.S的start汇编例程开始执行。这个例程进行一些基本的硬件设置,并调用/arch/i386/boot/compressed/head.S中的startup_32例程。startup_32例程设置一个基本的运行环境(如堆栈)后清除BSS段,调用/arch/i386/boot/compressed/misc.c中的decompress_kernel()解压缩内核。
内核被解压缩到内存中会再调用/arch/i386/kernel/head.S文件中的startup_32例程,这个新的startup_32例程(称为清除程序或进程0)会初始化页表,并启用内存分页机制,接着为任何可选的浮点单元(FPU)检测CPU的类型,并将其存储起来供以后使用。
这些都做完之后,/init/main.c中的start_kernel()函数被调用,进入与体系结构无关的Linux内核部分。
start_kernel()会调用一系列初始化函数来设置中断,执行进一步的内存配置。之后,/arch/i386/kernel/process.c中kernel_thread()被调用以启动第一个核心线程,该线程执行init()函数,而原执行序列会调用cpu_idle(),等待调度。
作为核心线程的init()函数完成外设及其驱动程序的加载和初始化,挂接根文件系统。init()打开/dev/console设备,重定向stdin、stdout和stderr到控制台。之后,它搜索文件系统中的init程序(也可以由“init=”命令行参数指定init程序),并使用execve()系统调用执行init()程序。搜索init程序的顺序为/sbin/init、/etc/init、/bin/init和/bin/sh。在嵌入式系统中,多数情况下,可以给内核传入一个简单的shell脚本来启动必需的嵌入式应用程序。
至此,漫长的Linux内核引导和启动过程就结束了,而init()对应的由start_kernel()创建的第一个线程也进入用户模式。
3.5 Linux下的C编程
3.5.1 Linux程序命名习惯
Linux程序的命名习惯和Windows程序的命名习惯及著名的匈牙利命名法有很大的不同。
在Windows程序中,习惯以如下方式命名宏、变量和函数:
1 |
|
这种命名方式在程序员中非常盛行,意思表达清晰且避免了匈牙利法的臃肿,单词之间通过首字母大写来区分。通过第一个单词的首字母是否大写可以区分名称属于变量还是属于函数,而看到整串的大写字母可以断定为宏。
但是Linux不以这种习惯命名,对应于上面的一段程序,在Linux程序的命名如下所示:
1 |
|
3.5.2 GNU C与ANSI C
Linux系统上可用的C编译器是GNU C编译器,它建立在自由软件基金会的编程许可证的基础上,因此可以自由发布。GNU C对标准C进行一系列扩展,以增强标准C的功能。
1. 零长度数组
GNU C允许使用零长度数组,在定义变长对象的头结构时,这个特性非常有用。例如:
1 | struct var_data |
char data[0]仅仅意味着程序中通过var_data结构体实例的data[index]成员可以访问len之后的第index个地址,它并没有为data[]数组分配内存,因此sizeof(struct var_data) = sizeof(int)。
假设struct var_data的数据域保存在struct var_data紧接着的内存区域,通过如下代码可以遍历这些数据:
1 | struct var_data s; |
2. case 范围
GNU C支持case x…y这样的语法,区间[x,y]的数都会满足这个case的条件,请看下面的代码:
1 | switch(ch) |
代码中的case ‘0’…’9’等价于标准C中的如下代码:
1 | case '0': case '1': case '2': case '3': case '4': |
3. 语句表达式
GNU C把包含在括号中的复合语句看作是一个表达式,称为语句表达式,它可以出现在任何允许表达式的地方。我们可以在语句表达式中使用原本只能在复合语句中使用的循环变量、局部变量等,例如:
1 |
|
因为重新定义了__X和__y这两个局部变量,所以以上述方式定义的宏将不会有副作用。在标准C中,对应的如下宏则会产生副作用。
1 |
代码min(++ia,++ib)会被展开为((++a) < (++y) ? (++a) : (++y)),传入宏的参数被增加两次。
4. typeof关键字
typeof(x)语句可以获得x的类型,因此,我们可以借助typeof重新定义min这个宏:
1 |
我们不需要像min_t(type,x,y)这个宏那样把type传入,因为通过typeof(x)、typeof(y)可以获得type。代码行(void)(&_x==&_y)的作用是检查_x和_y的类型是否一致。
5. 可变参数的宏
标准C只支持可变参数的函数,意味着函数的参数是不固定的,例如printf()函数的原型为:
1 | int printf(const char *fromat [,argument]...); |
而在GNU C中,宏也可以接受可变数目的参数,例如:
1 |
这里arg表示其余的参数可以是零个或多个,这些参数以及参数之间的逗号构成arg的值,在宏扩展时替换arg,例如下列代码:
1 | pr_debug("%s:%d",filename,line) |
会被扩展为:
1 | printk("%s:%d",filename,line) |
使用“##”的原因是处理arg不代表任何参数的情况,这时候,前面的逗号就变得多余了。使用“##”之后,GNU C预处理器会丢弃前面的逗号,这样,代码:
1 | pr_debug("success!\n"); |
会被周期的扩展为:
1 | printk("success!\n"); |
而不是:
1 | printk("success!\n",); |
6. 标号元素
标准C要求数组或结构体的初始化值必须以固定的顺序出现,在GNU C中,通过指定索引或结构体成员名,允许初始化值以任意顺序出现。
指定数组索引的方法是在初始化值前添加“[INDEX]=”,当然也可以用“[FIRST…LAST]=”的形式指定一个范围。例如下面的代码定义一个数组,并把其中的所有元素赋值为0:
1 | unsigned char data[MAX] = {[0 ... MAX - 1] = 0}; |
下面的代码借助结构体成员名初始化结构体:
1 | struct file_operation ext2_file_operations = |
但是,Linux2.6推荐类似的代码应该尽量采用标准C的方式,如下所示:
1 | struct file_operation ext2_file_operations = |
7. 当前函数名
GNU C预定义了两个标志符保存当前函数的名字,__FUNCTION__保存函数在源码中的名字,__PRETTY_FUNCTION__保存带语言特色的名字。在C函数中,这两个名字是相同的。
1 | void example() |
代码中的__FUNCTION__意味着字符串“example”。
8. 特殊属性声明
GNU C允许声明函数、变量和类型的特殊属性,以便进行手工的代码优化和定制代码检查的方法。指定一个声明的属性,只需要在声明后添加__attribute__((ATTRIBUTE))。其中ATRRIBUTE为属性说明,如果存在多个属性,则以逗号分离。GNU C支持noreturn、format、section、aligned、packed等十多个属性。
noreturn属性作用于函数,表示该函数从不返回。这会让编译器优化代码,并消除不必要的警告信息。例如:
1 |
|
format属性也用于函数,表示该函数使用printf、scanf或strftime风格的参数,指定format属性可以让编译器根据格式串检查参数类型。例如:
1 | asmlinkage int printk(const char *fmt,...) __attribute__((format(printf,1,2))); |
上述代码中的第一个参数是格式串,从第二个参数开始都会根据printf()函数的格式串规则检查参数。
unused属性作用于函数和变量,表示该函数或变量可能不会被用到,这个属性可以避免编译器产生警告信息。
aligned属性用于变量、结构体或联合体,指定变量、结构体或联合体的对界方式,以字节为单位,例如:
1 | struct example_struct |
表示该结构体的变量以4字节对齐。
packed属性作用于变量和类型,用于变量或结构体成员时表示使用最小可能的对齐,用于枚举、结构体或联合体类型时表示该类型使用最小的内存。例如:
1 | struct example_struct |
9. 内建函数
GNU C提供了大量的内建函数,其中大部分是标准的C库函数的GNU C编译器内建版本,例如memcpy()等,它们与对应的标准C库函数功能相同。
不属于库函数的其他内建函数的命名通常以__builtin开始,如下所示。
- 内建函数__builtin_return_address(LEVEL)返回当前函数或其调用者的返回地址,参数LEVEL指定调用栈的级数,如0表示当前函数的返回地址,1表示当前函数的调用者的返回地址。
- 内建函数__builtin_constant_p(EXP)用于判断一个值是否为编译时常数,如果参数EXP的值是常数,函数返回1,否则返回0。
- 内建函数__builtin_expect(EXP,C)用于为编译器提供分支预测信息,其返回值是整数表达式EXP的值,C的值必须是编译时常数。
例如,下面的代码检测第1个参数是否为编译时常数以确定采用参数版本还是非参数版本的代码:
1 |
3.5.3 do{}while(0)
在Linux内核中,经常会看到do{}while(0)这样的语句,许多人开始都会疑惑,认为do{}while(0)毫无意义,因为它只会执行一次,加不加do{}while(0)效果完全是一样的,其实do{}while(0)主要用于宏定义中。
这里用一个简单点的宏来演示:
1 |
假设这里去掉do{}while(0),即定义为:
1 |
do{}while(0)的使用完全是为了保证宏定义的使用者能无编译错误的使用宏,它不对其使用者作任何假设。
3.5.4 goto
用不用goto一直是一个著名的争议话题,Linux内核源代码中对goto的应用非常广泛,但是一般只限于错误处理中。用以错误处理的goto的用法简单而高效,只需保证在错误处理时注销、资源释放的顺序与正常的注册、释放申请的顺序相反。
3.6 总结
本章主要讲解了Linux内核和Linux内核编程的基础知识,为进行Linux驱动开发大小软件基础。
在Linux内核方面,本章主要介绍了Linux内核的发展史、组成、特点、源代码结构、内核编译方法及内核引导过程。
由于Linux驱动编程本质属于内核编程,因此掌握内核编程的基础知识显得尤为重要。本章在这方面主要讲解了在内核中新增程序及目录和编写Kconfig和Makefile的方法,并分析了Linux下C编程习惯以及Linux所使用的GNU C针对标准C的扩展语法。