可移植性
Linux是一个可移植性非常好的操作系统,它广泛支持许多不同体系结构的计算机。可移植性是指代码从一种体系结构移植到另外一种体系结构上的方便程度。我们都知道Linux是可移植的,因为它已经能够在各种不同的体系结构上运行了。但这种可移植性不是凭空得来的—-需要在编写可移植代码时就为此付出努力并坚持不懈。现在,这种努力已经开始得到回报了,移植Linux到新的系统上就很容易完成。本章中我们将讨论如何编写可移植的代码—-编写内核代码和驱动程序时,必须时刻牢记这个问题。
可移植操作系统
有些操作系统在设计时把可移植性作为头等大事之一,尽可能少地涉及与机器相关的代码。汇编代码用的少之又少,为了支持各种不同类别的体系结构,界面和功能在定义时都尽最大可能地具有普适性和抽象性。这么做最显著的汇报就是需要支持新的体系结构时,所需完成的工作要相对容易许多。一些移植性非常高而本身有比较简单的操作系统在支持新的体系结构时,可能只需要为此体系结构编写几百行专门的代码就行了。问题在于,体系结构相关的一些特性往往无法被支持,也不能对特定的机器进行手动优化。选择这种设计,就是利用代码的性能优化能力换取代码的可移植性。Minix、NetBSD和许多研究用的系统就是这种高度可移植操作系统的实例。
与之相反,还有一种操作系统完全不顾及可移植性,它们尽最大的可能追求代码的性能表现,尽可能多地使用汇编代码,压根就是只为在一种硬件体系结构使用。内核的特性都是围绕硬件提供的特性设计的。因此,将其移植到其他体系结构就等于再重新从头编写一个新的操作系统内核,而且即使进行移植,这种操作系统在其他体系结构上也会不适用。选择这种设计,就是用代码的可移植性换取代码的性能优化能力。这样的系统往往移植性好的系统更难维护。当然,这种系统对性能的要求不见得比对可移植性系统更强,不过它们还是愿意牺牲可移植性,而不乐意让性能打折扣。DOS和Windows 95便是这种设计方案的最好例证。
Linux在可移植性这个方向走的是中间路线。差不多所有的接口和核心代码都是独立于硬件体系结构的C语言代码。但是,在对性能要求很严格的部分,内核的特性会根据不同的硬件体系进行调整。举例来说,需要快速执行的和底层的代码都与硬件相关并且是用汇编语言写成的。这种实现方式使Linux在保持可移植性的同时兼顾对性能的优化。当可移植性妨碍性能发挥的时候,往往性能会被优先考虑。除此之外,代码就一定要保证可移植性。
一般来说,暴露在外的内核接口往往是与硬件体系结构无关的。如果函数的任何部分需要针对特殊的体系结构(无论是出于优化的目的还是作为一种必需的选择)提供支持的时候,这些部分都会被安置在独立的函数中,等待调用。每种被支持的体系结构都实现了一个与体系结构相关的函数,而且会链接到内核映像之中。
调度程序就是一个好例子。调度程序的主体程序存放在kernel/sched.c文件中,用C语言编写,与体系结构无关。可是,调度程序需要进行的一些工作,比如说切换处理器上下文的切换地址空间等,却不得不依靠相应的体系结构完成。于是,内核用C语言编写了函数context_switch()用于实现进程切换,而在它的内部,则会调用switch_to()和switch_mm()分别完成处理器上下文和地址空间的切换。
而对于Linux支持的每种体系结构,它们的switch_to()和switch_mm()实现都各不相同。所以,当Linux需要移植到新的体系结构上的时候,只需要重新编写和提供这样的函数就可以了。
与体系结构相关的代码都存放在arch/architecture/目录中,architecture是Linux支持的体系结构的简称。比如说,Intel x86体系结构对应的简称是x86(这种体系结构既支持x86-32又支持x86-64)。与这种体系结构相关的代码都存放在arhc/x86目录下。2.6系列内核支持的体系结构包括alpha、arm、avr32、blackfin、cris、frv、h8300、ia64、m32r、m68k、m68knommu、mips、mn10300、parisc、powerpc、s390、sh、sparc、um、x86和xtensa。
Linux移植史
当Linus最初把Linux带到这个无法预测的大千世界的时候,它只能在i386上运行。尽管这个操作系统通用性很强,代码也写得不错,可是可移植性在那时算不上是一个关注焦点。实际上,Linus还一度建议让Linux只在i386体系结构上驰骋。不过,人们还是在1993年开始把Linux向Digital Alpha体系结构上移植了。Digital Alpha是一种高性能现代计算机体系结构,它支持RISC的64位寻址。这与Linus最初选的i386无疑是天壤之别,虽然如此,最初的这次移植工作最终还是花费了将近一年时间,Alpha成为了i386后第一个被官方支持的体系结构。万事开头难,这次移植的挑战性是最大的,为了提高可移植性,内核中不少代码都被重写了。尽管这给整个移植带来了不小的工作量,可是效果是显著的,自此以后,移植变得简单轻松许多。
尽管第一个发行版只支持Intel i386,但1.2版的内核就可以支持Digital Alpha、Intel x86、MIPS和SPARC—-虽然支持的不是很完善,而且带些实验性质。
在2.0版内核中,加入了对Motorola 68K和PowerPC的官方支持,而原1.2版支持的体系结构也纳入了官方支持的范畴,并且稳定下来。
2.2版内核加入了对更多体系结构的支持,新增了对ARMS、IBM S390和UltraSPARC的支持。没过几年,2.4版内核支持的体系结构就达到了15个,像CRIS、IA_64、64位MIPS、HPPA_RISC、64位IBM S/390和Hitachi SH都被加进来了。
当前的2.6内核把体系结构的数目进一步提高到了21个,有不含MMU的AVR、FR-V和Motorola 68K以及M32xxx、H8/300、IBM POWER、Xtensa,甚至还提供了用户模式(Usermode)Linux(一个在Linux虚拟机上运行的内核版本)。
每一种体系结构本身就可以支持不同的芯片和机型。像被支持的ARM和PowerPC等体系结构,它们就可以支持很多不同的芯片和机型。其他的体系结构。比如说x86和SPARC,它们可以支持32位和64位不同的处理器。所以说,尽管Linux移植到了21种基本体系结构上,但实际上可以运行它的机器的数目大得多。
字长和数据类型
能够由机器一次完成处理的数据称为字。这和我们在文档中用字符(8位)和页(4KB或8KB)来计量数据是相似的。字是指位的整数数目—-比如说,1、2、4、8等。但人们说某个机器是多少位的时候,他们其实说的是该机器的字长。比如说,当人们说Intel i7是64位芯片时,他们的意思是奔腾的字长为64位,也就是8字节。
处理器通用寄存器的大小和它的字长是相同的。一般来说,对于一个体系结构,它各个部件的宽度(比如说内存总线)最少要和它的字长一样大。虽然物理地址空间有时候会比字长小,但虚拟地址空间的大小也等于字长,至少Linux支持的体系结构中都是这样的。此外,C语言定义的long类型总是对等于机器的字长,而int类型有时会比字长小。比如说,Alpha是64机器,所以它的寄存器、指针和long类型都是64位长度的,而int类型是32位的。Alpha机每一次可以访问和操作一个64位长的数据。
字、双字以及混合
有些操作系统和处理器不把它们的标准字长称作字,相反,出于历史原因和某种主观的命名习惯,它们用字来代表一些固定长度的数据类型。比如说,一些系统根据长度把数据划分为字节(byte,8位)、字(word,16位),双字(double words,32位)和四字(quad words,64位),而实际上该机是32位的。在本书中(在Linux中一般也是这样),像我们前面所讨论的那样,一个字就代表处理器的字长。
对于支持的每一种体系结构,Linux都要将<asm/types.h>中的BITS_PER_LONG定义为C long类型的长度,也就是系统的字长。下表是Linux支持的体系结构和它们的字长的对照表。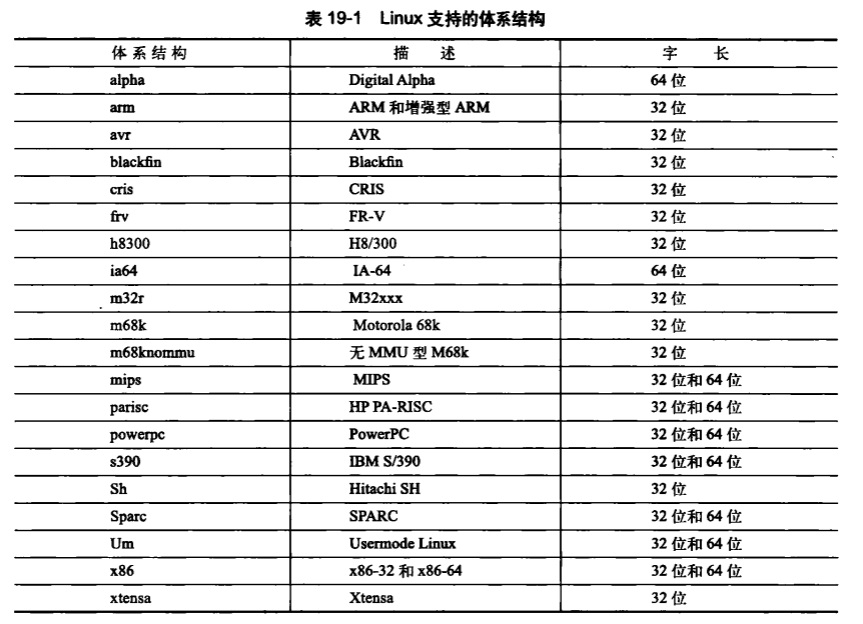
一般而言,Linux对于一种体系结构都会分别实现32位和64位的不同版本。比如,在2.6内核的早期版本中,内核就同时有i386和x86-64,mips和mips64,以及ppc和ppc64。但现在,经过大家的努力,这些体系结构均放在arch/目录下,每个代码既支持32位又支持64位。
C语言虽然规定了变量的最小长度,但是没有规定变量具体的标准长度,它们可以根据实现变化。C语言的标准数据类型长度随体系结构变化这一特性不断引起争议。好的一面是标准数据类型可以充分利用不同体系结构变化的字长而无须明确定义长度。C语言中long类型的长度就被确定为机器的字长。不好的一面是在编程时不能对标准的C数据类型进行大小的假定,没有什么能够保障int一定和long的长度是相同的。
情况其实还会更加复杂,因为用户空间使用的数据类型和内核空间的数据类型不一定要相互关联。sparc64体系结构就提供了32位的用户空间,其中指针、int和long的长度都是32位。而在内核空间,它的int长度是32位,指针和long的长度却是64。没有什么标准来规范这些。
牢记下述准则:
- ANSI C标准规定,一个char的长度一定是1字节。
- 尽管没有规定int类型的长度是32位,但在Linux当前所有支持的体系结构中,它都是32位的。
- short类型也类似,在当前所有支持的体系结构中,虽然没有明文规定,但是它都是16位的。
- 绝不应该假定指针和long的长度,在Linux当前支持的体系结构中,它们可以在32位和64位中变化。
- 由于不同的体系结构long的长度不同,绝不应该假设sizeof(int)=sizeof(long)。
- 类似地,也不要假设指针和int长度相等。
操作系统常用一个简单的助记符来描述此系统中数据类型的大小。比如,64位的Windows系统简称为LLP64,它说明long和指针的长度都是64位。64位的Linux系统可简记为LP64,即long和指针都是64位。32位的Linux系统简称为ILP32,即int、long和指针的长度均为32位。这些助记符可以一目了然地显示出操作系统所提供的字长大小,因为这种方法涉及一种权衡问题。
现在依次来分析ILP64、LP64和LLP64这三种情况。ILP64这种操作系统,int、long、指针的大小都是64位。这样的数据长度使得编程变得更加容易,因为C语言中的主要的数据类型大小是一样的(整型和指针大小的不匹配是编程中常出现的错误)。不过这样也会带来缺点,这种整型比我们平常所需的整型要大很多。在LP64操作系统中,程序员可以使用不同大小的整型,但必须注意整型的大小比指针类型要小。对于LLP64系统而言,程序员不仅要被迫接受int和long的大小相同,还要担心整型和指针之间的大小不匹配。大多数程序员都喜欢LP64类型,即Linux所采用的操作系统模型。
不透明类型
不透明数据类型隐藏了它们的内部格式或结构。在C语言中,它们就像黑盒一样。支持它们的语言不是很多。作为替代,开发者们利用typedef声明一个类型,把它叫做不透明类型,希望其他人别去把它重新转化回对应的那个标准C类型。通常开发者们在定义一套特别的接口时才会用到它们。比如说用来保存进程标识符的pid_t类型。该类型的实际长度被隐藏起来了—-尽管任何人都可以偷偷撩开它的面纱,发现它是一个int。如果所有代码都不显式地利用它的长度,那么改变时就不会引起什么争议,这种改变确实可能会出现:在老版本的Unix系统中,pid_t的定义是short类型。
另外一个不透明数据类型的例子是atomic_t。它放置的是一个可以进行原子操作的整型值。尽管这种数据就是一个int,但利用不透明类型可以帮助确保这些数据只在特殊的有关原子操作的函数中才会被使用。不透明类型还帮助我们隐藏了atomic_t类型的可用长度,但是该类型也并不总是完整的32位,比如在32位SPARC体系下长度就被限制。
内核还用到了其他一些不透明类型,包括dev_t、gid_t和uid_t等。
处理不透明类型时的原则是:
- 不要假设该类型的长度。这些类型在某些系统中可能是32位,而在其他系统中又可能是64位。并且,内核开发者可以任意修改这些类型的大小。
- 不要将该类型转化回其对应的C标准类型使用。
- 成为一个大小不可知论者。编程时要保证在该类型实际存储空间和格式发生变化时代码不受影响。
指定数据类型
内核中还有一些数据虽然无须用不透明的类型表示,但是它们定义成了指定的数据类型。在中断控制时用到的flag参数就是个例子,它应该存放在unsigned long类型中。
当存放和处理这些特别的数据时,一定要搞清楚它们对应的类型后再使用。把它们存放在其他(如unsigned int)类型中是一种常见错误。在32位机上这没什么问题,可是64位机上就会捅娄子。
长度明确的类型
作为一个程序员,你往往需要在程序中使用长度明确的数据。像操作硬件设备、进行网络通信和操作二进制文件时,通常都必须满足它们明确的内部要求。比如说,一块声卡可能用的是32位寄存器,一个网络包有一个16位字段,一个可执行文件有8位的cookie。在这种情况下,数据对应的类型应该长度明确。
内核在<asm/types.h>中定义了这些长度明确的类型,而该文件又被包含在文件<linux/types.h>中。下表有完整的清单。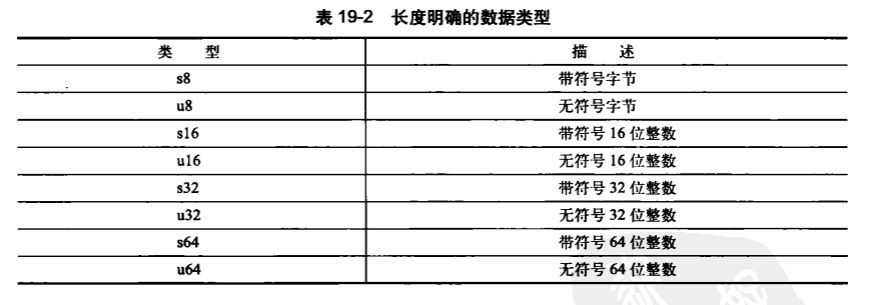
其中带符号的变量用得比较少。
这些长度明确的类型大部分都是通过typedef对标准的C类型进行映射得到的。在一个64位机上,它们看起来像:
1 | typedef signed char s8; |
而在32位机器上,它们可能定义成:
1 | typedef signed char s8; |
上述的这些类型只能在内核内使用,不可以在用户空间出现。这个限制是为了保护命名空间。不过内核对应这些不可见变量同时也定义了对应的用户可见的变量类型,这些类型与上面类型所不同的是增加了两个下划线前缀。比如,无符号32位整型对应的用户空间可见类型就是__u32。该类型除了名字有区别外,其他方面与u32相同。在内核中你可以任意使用这两个名字,但是如果是用户可见的类型,那必须使用下划线前缀的版本名,防止污染用户空间的命名空间。
char型的符号问题
C标准表示char类型可以带符号也可以不带符号,由具体的编译器、处理器或由它们两者共同决定到底char是带符号还是不带符号。
大部分体系结构上,char默认是带符号的,它可以自-128到127之间取值。也有一些例外,比如ARM体系结构上,char就是不带符号的,它的取值范围是0-255。
举例来说,在默认char不带符号的情况下,下面的代码实际会把255而不是把-1赋予i:
1 | char i = -1; |
而另一种机器上,默认char是带符号,就会确切地把-1赋予i。如果程序员本意是把-1保存在i中,那么前面的代码就该修改成:
1 | signed char i = -1; |
另外,如果程序员确实希望存储255,那么代码应该如下:
1 | unsigned char i = 255; |
如果在自己的代码中使用了char类型,那么要保证在带符号和不带符号的情况下代码都没问题。如果能明确要用的是哪一个,就直接声明它。
数据对齐
对齐是跟数据块在内存中的位置相关的话题。如果一个变量的内存地址正好是它长度的整数倍,它就称作自然对齐。举例来说,对于一个32位类型的数据,如果它在内存中的地址刚好可以被4整除,那它就是自然对齐的。也就是说,一个大小为2ⁿ字节的数据类型,它地址的最低有效位的后n位都应该为0。
一些体系结构对对齐的要求非常严格。通常像RISC的系统,载入未对齐的数据会导致处理器陷入(一种可处理的错误)。还有一些系统可以访问没有对齐的数据,只不过性能会下降。编写可移植性高的代码要避免对齐问题,保证所有的类型都能够自然对齐。
避免对齐引发的问题
编译器通常会通过让所有的数据自然对齐来避免引发对齐问题。实际上,内核开发者在对齐上不用花费太大心思—-只有搞gcc的那些老兄才应该为此犯愁呢。可是,当程序员使用指针太多,对数据的访问方式超出编译器的预期时,就会引发问题了。
一个数据类型长度较小,它本来是对齐的,如果你用一个指针进行类型转换,并且转换后的类型长度较大,那么通过改指针进行数据访问时就会引发对齐问题。也就是说,下面的代码是错误的:
1 | char wolf[] = "Like a wolf"; |
这个例子将一个指向char型的指针当作指向unsigned long型的指针来用,这会引起问题,因为此时会试图从一个并不能被4或8整除的内存地址上载入32位或64位的unsigned long型数据。
这种复杂的访问可能看起来有些模糊,不过通常就是如此。无论如何,这种错误出现了,所以应该小心。实际编程时错误可能不会像一些例子中那么明显或复杂。
非标准类型的对齐
前面提到了,对于标准数据类型来说,它的地址只要是其长度的整数倍就对齐了。而非标准的(复合的)C数据类型按照下列原则对齐:
- 对于数组,只要按照基本数据类型进行对齐就可以了,随后的所有元素自然能够对齐。
- 对于联合体,只要它包含的长度最大的数据类型能够对齐就可以了。
- 对于结构体,只要结构体中的每个元素能够正确地对齐就可以了。
结构体还要引入填补机制,这会引出下一个问题。
结构体填补
为了保证结构体中每一个成员都能够自然对齐,结构体要被填补。这点确保了当处理器访问结构中一个给定元素时,元素本身是对齐的。举个例子,下面是一个在32位机上的结构体:
1 | struct animal_struct { |
由于该结构不能准确地满足各个成员自然对齐,所以它在内存中可不是按照原样存放的。编译器会在内存中创建一个类似下面给出的结构体:
1 | struct animal_struct { |
填补的变量都是为了能够让数据自然对齐而加入的。第一个填充物占用了3个字节的空间,保证cat可以按照4字节对齐。这也自动使其他小的对象都对齐了,因为它们长度都比cat要小。第二个(也是最后的)填充是为了填补struct本身的大小。额外的这个填补使结构体的长度能够被4整除,这样,在由该结构体组成的数组中,每个数组项也就会自然对齐了。
注意,在大部分32位系统上,对于任何一个这样的结构体,sizeof(animal_struct)都会返回12。C编译器自动进行填补以保证自然对齐。
通常你可以通过重新排列结构体中的对象来避免填充。这样既可以得到一个较小的结构体,又能保证无须填补它也是自然对齐的。
1 | struct animal_struct { |
现在这个结构体只有8个字节大小了。不过,不是任何时候都可以这样对结构体进行调整的。举个例子,如果该结构体是某个标准的一部分,或者它是现有代码的一部分,那么它的成员次序就已经被定死了,虽然内核(缺少一个正式的ABI)相比用户空间来说,这种需求要少得多。还有些时候,因为一些原因必须使用某些固定的次序—-比如说,为了提高高速缓存的命中率进行优化时设定的变量次序。注意,ANSI C明确规定不允许编译器改变结构体内成员对象的次序—-它总是由程序员来决定。虽然编译器可以帮助你做填充,但是,如果使用-Wpadded flag标志,那么将使gcc在发现结构体被填充时产生警告。内核开发者需要注意结构体填补问题,特别是在整体使用时----这是指当需要通过网络发送它们或需要将它们写入文件的时候,因为不同体系结构之间所需要的填补也不尽相同。这也是为什么C语言没有提供一个内建的结构体比较操作符的原因之一。结构体内的填充字节中可能会包含垃圾信息,所以在结构体之间进行一字节一字节的比较就不大可能实现了。C语言的设计者感觉到最好还是由程序员自己为不同的情况编写比较函数,这样才能利用到结构体次序信息。
字节顺序
字节顺序是指在一个字中各个字节的顺序。处理器在对字取值时既可能将最低有效位所在的字节当作第一个字节,也可能将其当作最后一个字节。如果最高有效位所在的字节放在低字节位置上,其他字节依次放在高字节位置上,那么该字节顺序称作高位优先(big-endian)。如果最低有效位所在的字节放在高字节位置上,其他字节依次放在低字节位置上,那么就称作低位优先(little-endian)。
编写内核代码时不应该假设字节顺序是给定的哪一种(当然,如果你编写的是与体系结构相关的那部分代码就另当别论了)。Linux内核支持的机器中使用哪一种字节顺序的都有(甚至包括一些可以在启动的时候选择字节顺序的机器),适用性极强的代码应该两种字节顺序都支持。
下图是高位优先字节顺序的一个实例: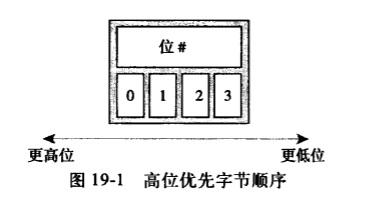
下图是低位优先字节顺序的一个实例: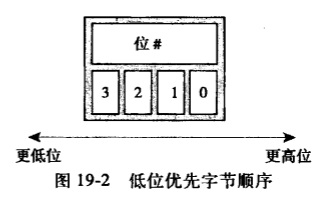
x86体系结构,不论32位机还是64位机,使用的都是低位优先字节顺序。而其他系统大多使用高位优先字节顺序。
让我们看看在实际编程时这些概念有什么意义。让我们参考一下存放在一个4字节的整型中的二进制数,它的十进制对应值是1027:
1 | 00000000 00000000 00000100 00000011 |
在内存中用高位优先和低位优先两种不同字节顺序存放时的比较如下表:
字节顺序比较
| 地址 | 高位优先 | 低位优先 |
|---|---|---|
| 0 | 00000000 | 00000011 |
| 1 | 00000000 | 00000100 |
| 2 | 00000100 | 00000000 |
| 3 | 00000011 | 00000000 |
注意
使用高位优先的体系结构把最高字节位存放在最小的内存地址上。这和低位优先形成了鲜明的对照。
最后一个例子,我们提供了如何判断给定的机器使用是高位优先还是低位优先字节顺序的代码:
1 | int x = 1; |
这段代码在用户空间和内核空间都能用。
对于Linux支持的每一种体系结构,相应的内核都会根据机器使用的字节顺序在它的<asm/byteorder.h>中定义__BIG_ENDIAN或__LITTLE_ENDIAN中的一个。
这个头文件还从include/linux/byteorder/中包含了一组宏命令用于完成字节顺序之间的相互转换。最常用的宏命令有:
1 | u32 __cpu_to_be32(u32); //把cpu字节顺序转换为高位优先字节顺序 |
这些转换能够把一种字节顺序变为另一种字节顺序。如果两种字节顺序本来就相同(比如,希望从本地字节顺序转化为高位优先字节顺序,而处理器本身使用的就是高位优先字节顺序),那么宏就什么都不做。否则,它们就进行转换。
时间
时间测量是另一个内核概念,它随着体系结构甚至内核版本的不同而不同。绝对不要假定时间中断发生的频率,也就是每秒产生的jiffies数目。相反,应该使用HZ来正确计量时间。这一点至关重要,因为不但不同的体系结构之间定时中断的频率不同,即使是在同一种体系结构上,两个不同版本的内核之间这种频率也不尽相同。
举个例子,在x86系统上,HZ设定为100。也就是说,定时中断每秒发生100次,也就是每10ms一次。可是在2.6版以前,x86上HZ定为1000。而其他体系结构上的数值各不相同:alpha的HZ是1024而ARM的HZ是100。
绝对不要用jiffies直接去和1000这样的数值比较,认为这样做大体上不会出问题是要不得的。计量时间的正确方法是乘以或除以HZ。比如:
1 | HZ //1秒 |
HZ定义在文件<asm/param.h>中。
页长度
当处理用页管理的内存时,绝对不要假设页的长度。在x86-32下编程的程序员往往错误地认为一页的大小就是4KB。尽管x86-32机器上使用的页确实是4KB,但是其他不同的体系结构使用的页长度可能不同。实际上有些体系结构还同时支持多种不同长度的页。下表列举了各种体系结构使用的页的长度。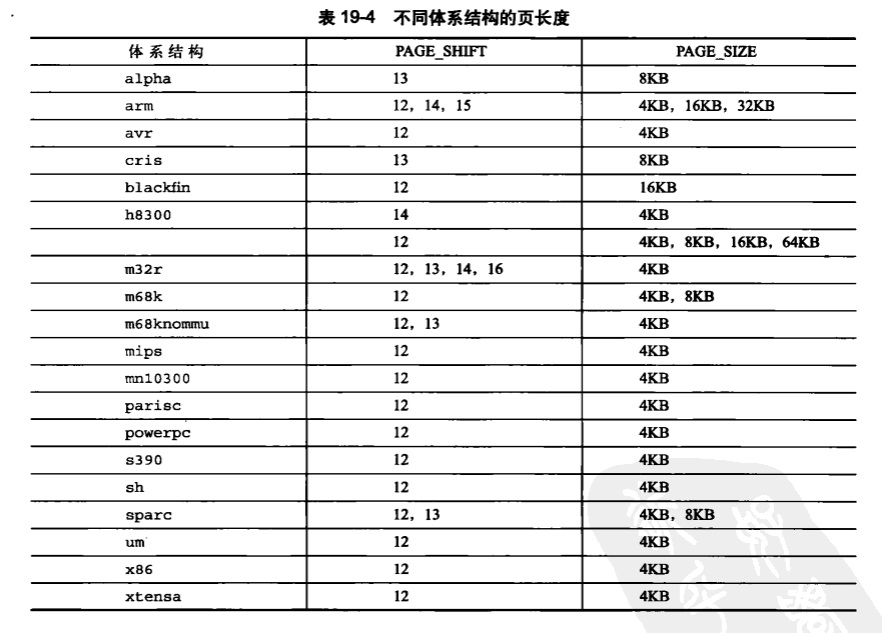
当处理用页组织管理的内存时,通过PAGE_SIZE以字节数来表示页长度。而PAGE_SHIFT这个值定义了从最右端屏蔽多少位能够得到该地址对应的页的页号。举例来说,在页长为4KB的x86-32位机上,PAGE_SIZE为4096而PAGE_SHIFT为12。它们都定义于<asm/page.h>中。
处理器排序
有些处理器严格限制指令排序,代码指定的所有装载或存储指令都不能被重新排序;而另外一些体系结构对排序要求则很弱,可以自行排序指令序列。
在代码中,如果在对排序要求最弱的体系结构上,要保证指令执行顺序。那么就必须使用诸如rmb()和wmb()等恰当的内存屏障来确保处理器以正确顺序提交装载和存储指令。
SMP、内核抢占、高端内存
在讨论可移植性的地方加入有关并发处理、内核抢占和高端内存的部分看起来似乎不太恰当。毕竟,这些都不是会影响到操作系统的硬件之间有所差异的那些特性;恰恰相反,它们都是Linux内核本身的一些功能,硬件体系结构根本感知不到它们的存在。但是,它们代表的其实都是可配置的重要选项,而你的代码应该充分考虑到对它们的支持。就是说,只有在编程时就针对SMP/内核抢占/高端内存进行了考虑,代码才会无论内核怎样配置,都能身处安全之中。再对前面那些保证可移植性范的规范下加上这几条:
- 假设你的代码会在SMP系统上运行,要正确的选择和使用锁。
- 假设你的代码会在支持内核抢占的情况下运行,要正确的选择和使用锁和内核抢占语句。
- 假设你的代码会运行在使用高端内存(非永久映射内存)的系统上,必要时使用kmap()。
小结
要想写出可移植性好、简洁、合适的内核代码,要注意以下两点:
- 编码尽量选取最大公因子:假定任何事情都可能发生,任何潜在的约束也都存在。
- 编码尽量选取最小公约数:不要假定给定的内核特性是可用的,仅仅需要最小的体系结构功能。
编写可移植的代码需要考虑许多问题:字长、数据类型、填充、对齐、字节次序、符号、字节顺序、页大小以及处理器的加载/存储排序等。对于绝大多数内核开发来说,可能主要考虑的问题就是保证正确使用数据类型,虽然如此,说不定有朝一日,还是会有些与古老的体系结构有关的问题突然跳出来困扰你。所以说理解移植性的重要性,并且在开发内核过程中时刻注意编写简洁、可移植的代码是非常重要的。