虚拟文件系统
虚拟文件系统(有时也称作虚拟文件交换,更常见的是简称VFS)作为内核子系统,为用户空间程序提供了文件和文件系统相关的接口。系统中所有文件系统不但依赖VFS共存,而且也依靠VFS系统协同工作。通过虚拟文件系统,程序可以利用标准的Unix系统调用对不同的文件系统,甚至不同介质上的文件系统进行读写操作,如下图所示: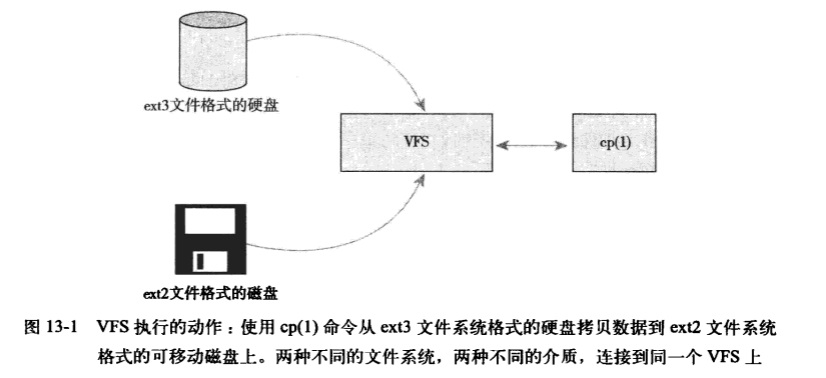
通用文件系统接口
VFS使得用户可以直接使用open()、read()和write()这样的系统调用而无须考虑具体文件系统和实际物理介质。现在听起来这并没什么新奇的,但是,使得这些通用的系统调用可以跨越各种文件系统和不同介质执行,绝非是微不足道的成绩。更了不起的是,系统调用可以在这些不同的文件系统和介质之间执行—-我们可以使用标准的系统调用从一个文件系统拷贝或移动数据到另一个文件系统。老实的操作系统(比如DOS)是无力完成上述工作的,任何对非本地文件系统的访问都必须依靠特殊工具才能完成。正是由于现代操作系统引入抽象层,比如Linux,通过虚拟接口访问文件系统,才使得这种协作性和泛型存取成为可能。
新的文件系统和新类型的存储介质都能找到进入Linux之路,程序无须重写,甚至无须重新编译。在本章中,我们将讨论VFS,它把各种不同的文件系统抽象后采用统一的方式进行操作。在第14章中,我们将讨论块I/O层,它支持各种各样的存储设备—-从CD到蓝光光盘,从硬件设备再到压缩闪存。VFS和块I/O相结合,提供抽象、接口以及交融,使得用户空间的程序调用统一的系统调用访问各种文件,不管文件系统是什么,也不管文件系统位于何种介质,采用的命名策略是统一的。
文件系统抽象层
之所以可以使用这种通用接口对所有类型的文件系统进行操作,是因为内核在它的底层文件系统接口上建立一个抽象层。该抽象层使Linux能够支持各种文件系统,即便是它们在功能和行为上存在很大差别。为了支持多文件系统,VFS提供了一个通用文件系统模型,该模型囊括了任何文件系统的常用功能集和行为。当然,该模型偏重于Unix风格的文件系统。但即使这样,Linux仍然可以支持很多种差异很大的文件系统,从DOS系统的FAT到Windows系统的NTFS,再到各种Unix风格文件系统和Linux特有的文件系统。VFS抽象层之所以能够衔接各种各样的文件系统,是因为它定义了所有文件系统都支持的、基本的、概念上的接口和数据结构。同时实际文件系统也将自身的诸如“如何打开文件”,“目录是什么”等概念在形式上与VFS的定义保持一致。因为实际文件系统的代码在统一的接口和数据结构下隐藏了具体的实现细节,所以在VFS层和内核的其他部分看来,所有文件系统都是相同的,它们都支持像文件和目录这样的概念,同时也支持像创建文件和删除文件这样的操作。内核通过抽象层能够方便、简单地支持各种类型的文件系统。实际文件系统通过编程通过VFS所期望的抽象接口和数据结构,这样,内核就可以毫不费力地和任何文件系统协同工作,并且这样提供给用户空间的接口,也可以和任何文件系统无缝地连接在一起,完成实际工作。
其实在内核中,除了文件系统本身外,其他部分并不需要了解文件系统的内部细节。比如一个简单的用户空间程序执行如下的操作:
1 | ret = write(fd,buf,len); |
该系统调用将buf指针指向的长度为len字节的数据写入文件描述符fd对应的文件的当前位置。这个系统调用首先被一个通用系统调用sys_write()处理,sys_write()函数要找到fd所在的文件系统实际给出的是哪个写操作,然后再执行该操作。实际文件系统的写方法是文件系统实现的一部分,数据最终通过该操作写入介质(或执行这个文件系统想要完成的写动作)。下图描述了从用户空间的write()调用到数据被写入磁盘介质的整个流程。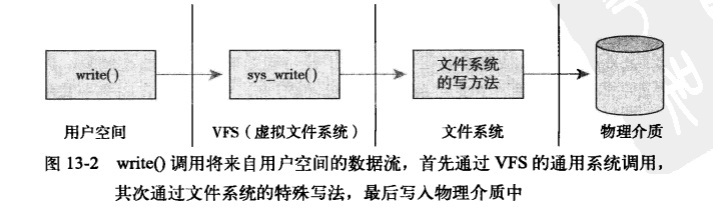
一方面,系统调用是通用VFS接口,提供给用户空间的前端;另一方面,系统调用是具体文件系统的后端,处理实现细节,接下来的小节中我们会具体看到VFS抽象模型以及它提供的接口。
Unix文件系统
Unix使用了四种和文件系统相关的传统抽象概念:文件、目录项、索引节点和安装点(mount point)。
从本质上讲文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。文件系统的通用操作包含创建、删除和安装等。在Unix中,文件系统被安装在一个特定的安装点上,该安装点在全局层次结构中被称作命名空间,所有的已安装文件系统都作为根文件系统树的枝叶出现在系统中。与这种单一、统一的树形成鲜明对照的就是DOS和Windows的表现,它们将文件的命名空间分类为驱动字母,例如C:。这种将命名空间划分为设备和分区的做法,相当于把硬件细节“泄露”给文件系统抽象层。对用户而言,如此的描述有点随意,甚至产生混淆,这是Linux统一命名空间所不屑一顾的。
文件其实可以做一个有序字符串,字符串中第一个字节是文件的头,最后一个字节是文件的尾。每一个文件为了便于系统和用户识别,都被分配了一个便于理解的名字。典型的文件操作有读、写、创建和删除等。Unix文件的概念与面向记录的文件系统形成鲜明的对照。面向记录的文件系统提供更丰富、更结构化的表示,而简单的面向字节流抽象的Unix文件则以简单性和相当的灵活性为代价。
文件通过目录组织起来,文件目录好比一个文件夹,用来容纳相关文件。因为目录也可以包含其他目录,即子目录,所以目录可以层层嵌套,形成文件路径。路径中的每一部分都被称作目录条目。“/home/wolfman/butter”是文件路径的一个例子—-根目录/,目录home,wolfman和文件butter都是目录条目,它们统称为目录项。在Unix中,目录属于普通文件,它列出包含在其中的所有文件。由于VFS把目录当作文件对待,所以可以对目录执行和文件系统的操作。
Unix系统将文件的相关信息和文件本身这两个概念加以区分,例如访问控制权限、大小、拥有者、创建时间等信息。文件相关信息,有时被称作文件的元数据(也就是说,文件的相关数据),被存储在一个单独的数据结构中,该结构被称为索引节点(inode),它其实是index node的缩写,不过近来术语“inode”使用得更为普遍一些。
所有这些信息都和文件系统的控制信息密切相关,文件系统的控制信息存储在超级块中,超级块是一种包含文件系统信息的数据结构。有时,把这些收集起来的信息称为文件系统数据元,它集单独文件信息和文件系统的信息于一身。
一直以来,Unix文件系统在它们物理磁盘布局中也是按照上述概念实现的。比如说在磁盘上,文件(目录也属于文件)信息按照索引节点形式存储在单独的块中;控制信息被集中存储在磁盘的超级块中,等等。Unix中文件的概念从物理上被映射到存储介质。Linux的VFS的设计目标就是要保证能与支持和实现了这些概念的文件系统协同工作。像如FAT或NTFS这样的非Unix风格的文件系统,虽然也可以在Linux上工作,但是它们必须经过封装,提供一个符合这些概念的界面。比如,即使一个文件系统不支持索引节点,它也必须在内存中装配索引节点结构体,就像它本身包含索引节点一样。再比如,如果一个文件系统将目录看做一种特殊对象,那么想要使用VFS,就必须将目录重新表示为文件形式。通常,这种转换需要在使用现场(on the fly)引入一些特殊处理,使得非Unix文件系统能够兼容Unix文件系统的使用规则并满足VFS的需求。这种文件系统当然仍能工作,但是其带来的开销则不可思议(开销太大)。
VFS对象及其数据结构
VFS其实采用的是面向对象的设计思路,使用一组数据结构来代表通用文件对象。这些数据结构类似于对象。因为内核纯粹使用C语言代码实现,没有直接利用面向对象的语言,所以内核中的数据结构都使用C语言的结构体实现,而这些结构体包含数据的同时也包含操作这些数据的函数指针,其中的操作函数由具体文件系统实现。
VFS中有四个主要的对象类型,它们分别是:
超级块对象,它代表一个具体的已安装文件系统。索引节点对象,它代表一个具体文件。目录项文件,它代表一个目录项,是路径的一个组成部分。文件对象,它代表由进程打开的文件。
注意,因为VFS将目录作为一个文件来处理,所以不存在目录对象。回忆本章前面所提到的目录项代表的是路径中的一个组成部分,它可能包括一个普通文件。换句话说,目录项不同于目录,但目录却是另一种形式的文件。
每个主要对象中都包含一个操作对象,这些操作对象描述了内核针对主要对象可以使用的方法:
- super_operations对象,其中包括内核针对特定文件系统所能调用的方法,比如write_inode()和sync_fs()等方法。
- inode_operations对象,其中包括内核针对特定文件所能调用的方法,比如create()和link()等方法。
- dentry_operations对象,其中包括内核针对特定目录所能调用的方法,比如d_compare()和d_delete()等方法。
- file_operations对象,其中包括进程针对已打开文件所能调用的方法,比如read()和write()等方法。
操作对象作为一个结构体指针来实现,此结构体中包含指向操作其父对象的函数指针。对于其中许多方法来说,可以继承使用VFS提供的通用函数,如果通用函数提供的基本概念无法满足需要,那么就必须使用实际文件系统的独有方法填充这些函数指针,使其指向文件系统实例。
再次提醒,我们这里说的对象就是指结构体,而不是像C++或Java那样的真正的对象数据类类型。但是这些结构体的确代表的是一个对象,它含有相关的数据和对这些数据的操作,所以可以说它们就是对象。
VFS使用大量的结构体对象,它所包括的对象远远多于上面提到的这几种主要对象。比如每个注册的文件系统都由file_system_type结构体来表示,它描述了文件系统及其性能;另外,每一个安装点也都用vfsmount结构体表示,它包含的是安装点的相关信息,如位置和安装标志等。
在本章的最后还要介绍两个与进程相关的结构体,它们描述了文件系统以及和进程相关的文件,分别是fs_struct结构体和file结构体。
下一节将讨论这些对象以及它们在VFS层的实现中扮演的角色。
超级块对象
各种文件系统都必须实现超级快对象,该对象用于存储特定文件系统的信息,通常对应于存放在磁盘特定扇区中的文件系统超级块或文件系统控制块。对于并非基于磁盘的文件系统(基于内存的文件系统sysfs),它们会在使用现场创建超级块并将其保存到内存中。
超级块对象由super_block结构体表示,定义在文件<linux/fs.h>中,下面给出它的结构和各个域的描述:
1 | struct super_block { |
创建、管理和撤销超级块对象的代码位于文件fs/super.c中。超级块对象通过alloc_super()函数创建并初始化。在文件系统安装时,文件系统会调用该函数以便从磁盘读取文件系统超级块,并且将信息填充到内存中的超级块对象中。
超级块操作
超级块对象中最重要的一个域是s_op,它指向超级块的操作函数表。超级块操作函数由super_operations结构体表示,定义在文件<linux/fs.h>中,其形式如下:
1 | struct super_operations { |
该结构体中的每一项都是一个指向超级块操作函数的指针,超级块操作函数执行文件系统和索引节点的底层操作。
当文件系统需要对其超级块执行操作时,首先要在超级块对象中寻找需要的操作方法。比如,如果一个文件系统要写自己的超级块,需要调用:
1 | sb->s_op->write_super(sb); |
在这个调用中,sb是指向文件系统超级块的指针,沿着该指针进入超级块操作函数表s_op,并从表中取得希望得到的write_siper()函数,该函数执行写入超级块的实际操作。注意,尽管write_super()方法来自超级块,但是在调用时,还是要把超级块作为参数传递给它,这是因为C语言中缺少面向对象的支持,而在C++中,使用如下的调用就足够了:
1 | sb.write_super(); |
由于在C语言中无法直接得到操作函数的父对象,所以必须将父对象以参数的形式传给操作函数。
下面给出super_operation中,超级块操作函数的用法。
1 | struct inode *alloc_inode(struct super_block *sb); |
在给定的超级块下创建和初始化一个新的索引节点对象。
1 | void destroy_inode(struct inode *inode); |
用于释放给定的索引节点。
1 | void dirty_inode(struct inode *inode); |
VFS在索引节点脏(被修改)时会调用此函数。日志文件系统(ext3、ext4)执行该函数进行日志更新。
1 | void write_inode(struct inode *inode,int wait); |
用于将给定的索引节点写入磁盘。wait参数指明写操作是否需要同步。
1 | void drop_inode(struct inode *inode); |
在最后一个指向索引节点的引用被释放后,VFS就会调用该函数。VFS只需要简单地删除这个索引节点之后,普通Unix文件就不会定义这个函数了。
1 | void delete_inode(struct inode *inode); |
用于从磁盘上删除给定的索引节点。
1 | void put_super(struct super_block *sb); |
在卸载文件系统时由VFS调用,用来释放超级块。调用者必须一直持有s_lock锁。
1 | void write_super(struct super_block *sb); |
用给定的超级块更新磁盘上的超级块。VFS通过该函数对内存中的超级块和磁盘中的超级块进行同步。调用者必须一直持有s_lock锁。
1 | int sync_fs(struct super_block *sb,int wait) |
使文件系统的数据元与磁盘上的文件系统同步。wait参数指定操作是否同步。
1 | void write_super_lockfs(struct super_block *sb); |
首先禁止对文件系统做改变,再使用给定的超级块更新磁盘上的超级块。目前LVM(逻辑卷标管理)会调用该函数。
1 | void unlockfs(struct super_block *sb); |
对文件系统解除锁定,它是write_super_lockfs()的逆操作。
1 | int statfs(struct super_block *sb,struct statfs *statfs); |
VFS通过调用该函数获取文件系统状态。指定文件系统相关的统计信息将放置再statfs中。
1 | int remount_fs(struct super_block *sb,int *flag,char *data); |
当指定新的安装选项重新安装文件系统时,VFS会调用该函数。调用者必须一直持有s_lock锁。
1 | void clear_inode(struct inode *inode); |
VFS调用该函数释放索引节点,并清空包含相关数据的所有页面。
1 | void unmount_begin(struct super_block *sb); |
VFS调用该函数中断安装操作。该函数被网络文件系统调用,如NFS。
所有以上函数都是由VFS在进程上下文中调用。除了dirty_inode(),其他函数在必要时都可以阻塞。
这其中的一些函数都是可选的。在超级块操作表中,文件系统可以将不需要的函数指针设置成NULL。如果VFS发现操作函数指针使NULL,那它要么就会调用通用函数执行相应操作,要么什么也不做,如何选择取决于具体操作。
索引节点对象
索引节点对象包含了在操作文件或目录时需要的全部信息。对于Unix风格的文件系统来说,这些信息可以从磁盘索引节点直接读入。如果一个文件系统没有索引节点,那么,不管这些相关信息在磁盘上是如何存放的,文件系统都必须从中提取这些信息。没有索引节点的文件系统通常将文件的描述信息作为文件的一部分来存放。这些文件系统与Unix风格的文件系统不同,没有将数据与控制信息分开存放。有些现代文件系统使用数据库来存储文件的数据。不管哪种情况、采取哪种方式,索引节点对象必须在内存中创建,以便于文件系统使用。
索引节点对象有inode结构体表示,它定义在文件<linux/fs.h>中,下面给出它的结构体和各项的描述:
1 | struct inode { |
一个索引节点代表文件系统中(但是索引节点仅当文件被访问时,才在内存中创建)的一个文件,它也可以是设备或管道这样的特殊文件。因此索引节点结构体中有一些和特殊文件相关的项。比如i_pipe项就指向一个代表有名管道的数据结构,i_bdev指向块设备结构体,i_cdev指向字符设备结构体。这三个指针被存放在一个共用体中,因为一个给定的索引节点每次只能表示三者之一(或三者均不)。
有时,某些文件系统可能并不能完整地包含索引节点结构体要求的所有信息。举个例子,有的文件系统可能并不记录文件的访问时间,这时,该文件系统就可以在实现中选择任意合适的办法来解决这个问题。它可以在i_atime中存储0,或者让i_atime等于i_mtime,或者只在内存中更新i_atime而不将其写回磁盘,或者由文件系统的实现者来决定。
索引节点操作
和超级块操作一样,索引节点对象中的inode_operations项也非常重要,因为它描述了VFS用以操作索引节点对象的所有方法,这些方法由文件系统实现。与超级块类似,对索引节点的操作调用方式如下:
1 | i->i_op->truncate(i); |
i指向给定的索引节点,truncate()函数是由索引节点i所在的文件系统定义的。inode_operations结构体定义在文件<linux/fs.h>中。
1 | struct inode_operations { |
下面这些接口由各种函数组成,在给定的节点上,可能由VFS执行这些函数,也可能由具体的文件系统执行:
1 | int create(struct inode *dir,struct dentry *dentry,int mode); |
VFS通过系统调用create()和open()来调用该函数,从而为dentry对象创建一个新的索引节点。在创建时使用mode指定的初始模式。
1 | struct dentry *lookup(struct inode *dir,struct dentry *dentry); |
该函数在特定目录中寻找索引节点,该索引节点要对应于dentry中给出的文件名。
1 | int link(struct dentry *old_dentry, |
该函数被系统调用link()调用,用来创建硬链接。硬链接名称由dentry参数指定,连接对象是dir目录中old_dentry目录项所代表的文件。
1 | int unlink(struct inode *dir,struct dentry *dentry); |
该函数被系统调用unlink()调用,从目录dir中删除由目录项dentry指定的索引节点对象。
1 | int symlink(struct inode *dir, |
该函数被系统调用symlink()调用,创建符号连接。该函数连接名称由symname指定,连接对象是dir目录中的dentry目录项。
1 | int mkdir(struct inode *dir, |
该函数被系统调用mkdir()调用,创建一个新目录。创建时使用mode指定的初始模式。
1 | int rmdir(struct inode *dir, |
该函数被系统调用rmdir()调用,删除dir目录中的dentry目录项代表的文件。
1 | int mknod(struct inode *dir, |
该函数被系统调用mknod()调用,创建特殊文件(设备文件、命名管道或套接字)。要创建的文件放在dir目录中,其目录项为dentry,管理的设备为rdev,初始权限由mode指定。
1 | int rename(struct inode *old_dir, |
VFS调用该函数来移动文件。文件源路径在old_dir目录中,源文件由old_dentry目录项指定,目标路径在new_dir目录中,目标文件由new_dentry指定。
1 | int readlink(struct dentry *dentry, |
该函数被系统调用readlink()调用,拷贝数据到特定的缓冲buffer中。拷贝的数据来自dentry指定的符号链接,拷贝的大小最大可达buflen字节。
1 | int follow_link(struct dentry *dentry, |
该函数由VFS调用,从一个符号连接查找它指向的索引节点。由dentry指向的连接被解析,其结果存放在由nd指向的nameidata结构体中。
1 | int put_link(struct dentry *dentry, |
在follow_link()调用之后,该函数由VFS调用进行清除工作。
1 | void truncate(struct inode *inode); |
该函数由VFS调用,修改文件的大小。在调用前,索引节点的i_size必须设置为预期的大小。
1 | int permission(struct inode *inode,int mask); |
该函数用来检查给定的inode所代表的文件是否允许特定的访问模式。如果允许特定的访问模式,返回零,否则返回负值的错误码。多数文件系统都将此区域设置为NULL,使用VFS提供的通用方法进行检查。这种检查操作仅仅比较索引节点对象中的访问模式位是否和给定的mask一致。比较复杂的系统(比如支持访问控制链(ACLS)的文件系统),需要使用特殊的permission()方法。
1 | int setattr(struct dentry *dentry, |
该函数被notify_change()调用,在修改索引节点后,通知发生了“改变事件”。
1 | int getattr(struct vfsmount *mnt, |
在通知索引节点需要从磁盘中更新时,VFS会调用该函数。
扩展属性允许key/value这样的一对值与文件相关联。
1 | int setxattr(struct dentry *dentry, |
该函数由VFS调用,给dentry指定的文件设置扩展属性。属性名为name,值为value。
1 | ssize_t getxattr(struct dentry *dentry, |
该函数由VFS调用,向value中拷贝给定文件的扩展属性name对应的数值。
1 | ssize_t listxattr(struct dentry *dentry, |
该函数将特定文件的所有属性列表拷贝到一个缓冲列表中。
1 | int removexattr(struct dentry *dentry, |
该函数从给定文件中删除指定的属性。
目录项对象
VFS把目录当作文件对待,所以路径在/bin/vi中,bin和vi都属于文件—-bin是特殊的目录文件而vi是一个普通文件,路径中的每个组成部分都由一个索引节点对象表示。虽然它们可以统一由索引节点表示,但是VFS经常需要执行目录相关的操作,比如路径名查找等。路径名查找需要解析路径中的每一个组成部分,不但要确保它有效,而且还需要再进一步寻找路径中的下一个部分。
为了方便查找操作,VFS引入了目录项的概念。每个dentry代表路径中的一个特定部分。对前一个例子来说,/、bin和vi都属于目录项对象。前两个是目录,最后一个是普通文件。必须明确一点:在路径中(包括普通文件在内),每一个部分都是目录项对象。解析一个路径并遍历其分量绝非简单的演练,它是耗时的、常规的字符串比较过程,执行耗时、代码繁琐。目录项对象的引入使得这个过程更加简单。
目录项也可包括安装点。在路径/mnt/cdrom/foo中,构成元素/、mnt、cdrom和foo都属于目录项对象。VFS在执行目录操作时会现场创建目录项对象。
目录项对象由dentry结构体表示,定义在文件<linux/decahe.h>中。下面给出该结构体和其中各项的描述:
1 | struct dentry { |
与前面的两个对象不同,目录项对象没有对应的磁盘数据结构,VFS根据字符串形式的路径名线程创建它。而且由于目录项对象并非真正保存在磁盘上,所以目录项结构体没有是否被修改的标志(也就是是否为脏,是否需要写回磁盘的标志)。
目录项状态
目录项对象有三种有效状态:被使用、未被使用和负状态。
一个被使用的目录项对应一个有效的索引节点(即d_inode指向相应的索引节点)并且表明该对象存在一个或多个使用者(即d_count为正值)。一个目录项处于被使用状态,意味着它正被VFS使用并且指向有效的数据,因此不能被丢弃。
一个未被使用的目录项对应一个有效的索引节点(d_inode指向一个索引节点),但是应指明VFS当前并未使用它(d_count为0).改目录项对象仍然指向一个有效对象,而且被保留在缓存中以便需要时再使用它。由于该目录项不会过早地被撤销,所以以后再需要它时,不必重新创建,与未缓存的目录项相比,这样使路径查找更迅速。但如果要回收内存的话,可以撤销未使用的目录项。
一个负状态的目录项没有对应的有效索引节点(d_inode为NULL),因为索引节点已被删除了,或路径不在正确了,但是目录项仍然保留,以便快速解析之后的路径查询。比如,一个守护进程不断地去试图打开并读取一个不存在的配置文件。open()系统调用不断地返回ENOENT,直到内核构建了这个路径、遍历磁盘上的目录结构体并检查这个文件的确不存在为止。即便这个失败的查找很浪费资源,但是将负状态缓存起来还是非常值得的。虽然负状态的目录项有些用处,但是如果有需要,可以撤销它,因为毕竟实际上很少用到它。
目录项对象释放后也可以保存到slab对象缓存中去。此时,任何VFS或文件系统代码都没有指向该目录项对象的有效引用。
目录项缓存
如果VFS层遍历路径名中所有的元素并将它们逐个的解析成目录项对象,还要达到最深层目录,将是一件非常费力的工作,会浪费大量的时间。所以内核将目录项对象缓存在目录项缓存中(简称dcache)。
目录项缓存包括三个部分:
- “被使用的”目录项链表。该链表通过索引节点对象中的i_dentry项连接相关的索引节点,因为一个给定的索引节点可能有多个链接,所以就可能有多个目录项对象,因此用一个链表来链接它们。
- “最近被使用的”双向链表。该链表含有未被使用的和负状态的目录项对象。由于该链表总是在头部插入目录项,所以链头节点的数据总比链尾的数据要新。当内核必须通过删除节点项回收内存时,会从链尾删除节点项,因为尾部的节点最旧,所以它们在近期内再次被使用的可能性最小。
- 散列表和相应的散列函数用来快速地将给定路径解析为相关目录项对象。
散列表由数组dentry_hashtable表示,其中每一个元素都是一个指向具有相同键值的目录项对象链表的指针。数组的大小取决于系统中物理内存的大小。
实际的散列表由d_hash()函数计算,它是内核提供给文件系统的唯一的一个散列函数。
查找散列表要通过d_lookup()函数,如果该函数在dcache中发现了与其相匹配的目录项对象,则匹配的对象被返回;否则,返回NULL指针。
举例说明,假设你需要在自己目录中编译一个源文件。/home/dracula/src/the_sun_sucks.c,每一次对文件进行访问(比如说,首先要打开它,然后要存储它,还要进行编译等),VFS都必须沿着嵌套的目录依次解析全部路径:/、home、dracula、src和最终的the_sun_sucks.c。为了避免每次访问该路径名都进行这种耗时的操作,VFS会先在目录缓存项中搜索路径名,如果找到了,就无须花费那么大的力气了。相反,如果该目录项在目录项缓存中并不存在,VFS就必须自己通过遍历文件系统为每个路径分量解析路径,解析完毕后,再将目录项对象加入dcache中,以便以后可以快速查找到它。
而dcache在一定意义上也提供对索引节点的缓存,也就是icache。和目录项对象相关的索引节点对象不会被释放,因为目录项会让相关索引节点的使用计数为正,这样就可以确保索引节点留在内存中。只要目录项被缓存,其相应的索引节点也就被缓存了。所以像前面的例子,只要路径名在缓存中找到了,那么相应的索引节点肯定也在内存中缓存着。
因为文件访问呈现空间与时间的局部性,所以对目录项和索引节点进行缓存非常有益。文件访问有时间上的局部性,是因为程序可能会一次又一次地访问相同的文件。因此,当一个文件被访问时,所缓存的相关目录项和索引节点不久被命中的概率较高。文件访问具有空间的局部性是因为程序可能在同一目录下访问多个文件,因此一个文件对应的目录项缓存后极有可能被命中,因为相关的文件可能下次又被使用。
目录项操作
dentry_operations结构体指明了VFS操作目录项的所有方法。
该结构定义在文件<linux/dcache.h>中。
1 | struct dentry_operations { |
下面给出函数的具体用法:
1 | int d_revalidate(struct dentry *dentry, struct nameidata *); |
该函数判断目录对象是否有效。VFS准备从dcache中使用一个目录项时,会调用该函数。大部分文件系统将该方法置NULL,因为它们认为dcache中的目录项对象总是有效的。
1 | int (*d_hash) (struct dentry *dentry, struct qstr *name); |
该函数为目录项生成散列值,当目录需要加入到散列表中时,VFS调用该函数。
1 | int (*d_compare) (struct dentry *dentry, struct qstr *name1, struct qstr *name2); |
VFS调用该函数来比较name1和name2这两个文件名。多数文件系统使用VFS默认的操作,仅仅作字符串比较。对有些文件系统,比如FAT,简单的字符串比较不能满足其需要。因为FAT文件系统不区分大小写,所以需要实现一种不区分大小写的字符串比较函数。注意使用该函数时需要加dcache_lock锁。
1 | int d_delete(struct dentry *dentry); |
在目录项对象的d_count计数值等于0时,VFS调用该函数。注意使用该函数需要加dcache_lock锁和目录项的d_lock。
1 | void d_release(struct dentry *dentry); |
在目录项对象将要被释放时,VFS调用该函数,默认情况下,它什么也不做。
1 | void d_iput(struct dentry *dentry,struct inode *inode); |
当一个目录项对象丢失了其相关的索引节点时(也就是说磁盘索引节点被删除了),VFS调用该函数。默认情况下VFS会调用iput()函数释放索引节点。如果文件系统重载了该函数,那么除了执行此文件系统特殊的工作外,还必须调用iput()函数。
文件对象
VFS的最后一个主要对象是文件对象。文件对象表示进程已打开的文件。如果我们站在用户角度来看待VFS,文件对象会首先进入我们的视野。进程直接处理的是文件,而不是超级块、索引节点或目录项。所以不必奇怪:文件对象包含我们非常熟悉的信息(比如访问模式,当前便宜等),同样道理,文件操作和我们非常熟悉的系统调用read()和write()等也很类似。
文件对象是已打开的文件在内存中的表示。该对象(不是物理文件)由相应的open()系统调用创建,由close()系统调用撤销,所有这些文件相关的调用实际上都是文件操作表中定义的方法。因为多个进程可以同时打开和操作同一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已打开文件,它反过来指向目录项对象(反过来指向索引节点),其实只有目录项对象才表示已打开的实际文件。虽然一个文件对应的文件对象不是唯一的,但对应的索引节点和目录项对象无疑是唯一的。
文件对象由file结构体表示,定义在文件<linux/fs.h>中,下面给出该结构体和各项的描述。
1 | struct file { |
类似于目录项对象,文件对象实际上没有对应的磁盘数据。所以在结构体中没有代表其对象是否为脏、是否需要写回磁盘的标志。文件对象通过f_dentry指针指向相关的目录项对象。目录项会指向相关的索引节点,索引节点会记录文件是否是脏的。
文件操作
和VFS的其他对象一样,文件操作表在文件对象中也非常重要。跟file结构体相关的操作与系统调用很类似,这些操作是标准Unix系统调用的基础。
文件对象的操作由file_operations结构体表示,定义在文件<linux/fs.h>中:
1 | struct file_operations { |
具体的文件系统可以为每一种操作做专门的实现,或者如果存在通用操作,也可以使用通用操作。一般在基于Unix的文件系统上,这些通用操作效果都不错。并不要求实际文件系统实现文件操作函数表中的所有方法—-虽然不实现最基础的那些操作显然是很不明智的,对不感兴趣的操作完全可以简单地将该函数指针置为NULL。
下面给出操作的用法说明:
1 | loff_t (*llseek) (struct file *file, loff_t offset, int origin); |
该函数用于更新偏移量指针,由系统调用llseek()调用它。
1 | ssize_t (*read) (struct file *file, char __user *buf, size_t count, loff_t *offset); |
该函数从给定文件的offset偏移处读取count字节的数据到buf中,同时更新文件指针。由系统调用read()调用它。
1 | ssize_t (*aio_read) (struct kiocb *icob, const struct iovec *buf, unsigned long count, loff_t *offset); |
该函数从iocb描述的文件里,以同步方式读取count字节的数据到buf中。由系统调用aio_read()调用它。
1 | ssize_t (*write) (struct file *file, const char __user *buf, size_t count, loff_t *offset); |
该函数从给定的buf中取出count字节的数据,写入给定文件的offset偏移处,同时更新文件指针。由系统调用write()调用它。
1 | ssize_t (*aio_write) (struct kiocb *icob, const struct iovec *buf, unsigned long count, loff_t *offse); |
该函数以同步方式从给定的buf中取出count字节的数据,写入由iocb描述的文件中。由系统调用aio_write()调用它。
1 | int (*readdir) (struct file *file, void *dirent, filldir_t filldir); |
该函数返回目录列表中的下一个目录。由系统调用readdir()调用它。
1 | unsigned int (*poll) (struct file *file, struct poll_table_struct *poll_table); |
该函数睡眠等待给定文件活动。由系统调用poll()调用它。
1 | int (*ioctl) (struct inode *inode, struct file *file, unsigned int cmd, unsigned long arg); |
该函数用来给设备发送目录参数对。当文件是一个被打开的设备节点时,可以通过它进行设置操作。由系统调用ioctl()调用它。调用者必须持有BKL。
1 | long (*unlocked_ioctl) (struct file *file, unsigned int cmd, unsigned long arg); |
其实现与ioctl()有类似的功能,只不过不需要调用者持有BKL。如果用户空间调用ioctl()系统调用,VFS便可以调用unlocked_ioctl()(凡是ioctl()出现的场所)。因此文件系统只需要实现其中的一个,一般优先实现unlocked_ioctl()。
1 | long (*compat_ioctl) (struct file *file, unsigned int cmd, unsigned long arg); |
该函数是ioctl()函数的可移植变种,被32位应用程序用在64位系统上。这个函数被设计成即使在64位的体系结构上对32位也是安全的,它可以进行必要的字大小转换。新的驱动程序应该设计自己的ioctl命令以便所有的驱动程序都是可移植的,从而使得compat_ioctl()和unlocked_ioctl()指向同一个函数。像compat_ioctl()和unlocked_ioctl()一样都不必持有BKL。
1 | int (*mmap) (struct file *file, struct vm_area_struct *vma); |
该函数将给定的文件映射到指定的地址空间上。由系统调用mmap()调用它。
1 | int (*open) (struct inode *inode, struct file *file); |
该函数创建一个新的文件对象,并将它和相应的索引节点对象关联起来。由系统调用open()调用它。
1 | int flush(struct file *file); |
当已打开文件的引用计数减少时,该函数被VFS调用。它的作用根据具体文件系统而定。
1 | int release(struct inode *inode,struct file *file); |
当文件的最后一个引用被注销时(比如,当最后一个共享文件描述符的进程调用了close()或退出时),该函数会被VFS调用。它的作用根据具体文件系统而定。
1 | int (*fsync) (struct file *file, struct dentry *dentry, int datasync); |
将给定文件的所有被缓存数据写回磁盘。由系统调用fsync()调用它。
1 | int (*aio_fsync) (struct kiocb *iocb, int datasync); |
将iocb描述的文件的所有被缓存数据写回到磁盘。由系统调用aio_fsync()调用它。
1 | int (*fasync) (int fd, struct file *file, int on); |
该函数用于打开或关闭异步I/O的通告信号。
1 | int (*lock) (struct file *file, int cmd, struct file_lock *lock); |
该函数用于给指定文件上锁。
1 | ssize_t readv(struct file *file,const struct iovec *vector,unsigned long count,loff_t *offset); |
该函数从给定文件中读取数据,并将其写入由vector描述的count个缓冲中去,同时增加文件的偏移量。由系统调用readv()调用它。
1 | ssie_t writev(struct file *file,const struct iovec *vector,unsigned long count,loff_t *offset) |
该函数将由vector描述的count个缓冲中的数据写入到由file指定的文件中去,同时减小文件的偏移量。由系统调用writev()调用它。
1 | ssize_t (*sendfile) (struct file *file, loff_t *offset, size_t size, read_actor_t actor, void *target); |
该函数用于从一个文件拷贝数据到另一个文件中,它执行的拷贝操作完全在内核中完成,避免了向用户空间进行不必要的拷贝。由系统调用sendfile()调用它。
1 | ssize_t (*sendpage) (struct file *file, struct page *page, int offset, size_t size, loff_t *pos, int more); |
该函数用来从一个文件向另一个文件发送数据。
1 | unsigned long (*get_unmapped_area)(struct file *file, unsigned long addr, unsigned long offset, unsigned long offset, unsigned long flags); |
该函数用于获取未使用的地址空间来映射给定的文件。
1 | int check_flags(int flags); |
当给出SETFL命令时,这个函数用来传递给fcntl()系统调用的flags的有效性。与大多数VFS操作一样,文件系统不必实现check_flags()—-目前,只有在NFS文件系统上实现了。这个函数能使文件系统限制无效的SETFL标志,不进行限制的话,普通的fcntl()函数能使标志生效。在NFS文件系统中,不允许把O_APPEND和O_DIRENT相结合。
1 | int (*flock) (struct file *filp, int cmd, struct file_lock *fl); |
这个函数用来实现flock()系统调用,该调用提供忠告锁。
如此之多的ioctl
不久之前,只有一个单独的ioctl方法。如今,有三个相关的方法。unlocked_ioctl()和ioctl相同,不过之前在无大内核锁(BKL)情况下被调用。因此函数的作者必须确保适当的同步。因为大内核锁是粗粒度、低效的锁,驱动程序应当实现unlocked_ioctl()而不是ioctl()。
compat_ioctl()也在无大内核锁的情况下被调用,但是它的目的是为64位的系统提供32位ioctl的兼容方法。至于你如何实现它取决于现有的ioctl命令。早期的驱动程序隐含有确定大小的类型(如long),应该实现适用于32位应用的compat_ioctl()方法。这通常意味着把32位值转换为64位内核中合适的类型。新驱动程序重新设计ioctl命令,应该确保所有的参数和数据都有明确大小的数据类型,在32位系统上运行32位应用是安全的,在64位系统上运行32位应用也是安全的,在64位系统上运行64位应用更是安全的。这些驱动程序可以让compat_ioctl()函数指针和unlocked_ioctl()函数指针指向同一函数。
和文件系统相关的数据结构
除了以上几种VFS基础对象之外,内核还使用了另外一些标准数据结构来管理文件系统的其他相关数据。第一个对象是file_system_type,用来描述各种特定文件系统类型,比如ext3、ext4或UDF。第二个结构体是vfsmount,用来描述一个安装文件系统的实例。
因为Linux支持众多不同的文件系统,所以内核必须由一个特殊的结构来描述每种文件系统的功能和行为。file_system_type结构体被定义在<linux/fs.h>中,具体实现如下:
1 | struct file_system_type { |
get_sb()函数从磁盘上读取超级块,并且在文件系统被安装时,在内存中组装超级块对象。剩余的函数描述文件系统的属性。
每种文件系统,不管有多少个实例系统安装到系统中,还是根本就没有安装到系统中,都只有一个file_system_type结构。
更有趣的是,当文件系统被实际安装时,将有一个vfsmount结构体在安装点被创建。该结构体用来代表文件系统的实例—-换句话说,代表一个安装点。
vfsmount结构被定义在<linux/mount.h>中,下面是具体结构:
1 | struct vfsmount { |
理清文件系统和所有其他安装点间的关系,是维护所有安装点中最复杂的工作。所以vfsmount结构体中维护的各种链表就是为了能够跟踪这些关联信息。
vfsmount结构还保存了在安装时指定的标志信息,该信息存储在mnt_flags域中。下表列出了标准的安装标志:
| 标志 | 描述 |
|---|---|
| MNT_NOSUID | 禁止该文件系统的可执行文件设置setuid和setgid标志 |
| MNT_MODEV | 禁止访问该文件系统上的设备文件 |
| MNT_NOEXEC | 禁止执行该文件系统上的可执行文件 |
安装那些管理员不充分信任的移动设备时,这些标志很有用处。它们和其他一些很少用的标志一起定义在<linux/mount.h>中。
和进程相关的数据结构
系统中的每一个进程都有自己的一组打开的文件,像根文件系统、当前工作目录、安装点等。有三个数据结构将VFS层和系统的进程紧密联系在一起,它们分别是:file_struct、fs_struct和namespace结构体。
file_struct结构体定义在文件<linux/fdtable.h>中。该结构体由进程描述符中的file目录项指向。所有与单个进程(pre-porcess)相关的信息(如打开的文件及文件描述符)都包含在其中,其结构和描述如下:
1 | struct files_struct { |
fd_array数组指针指向已打开的文件对象。因为NR_OPEN_DEFAULT等于BITS_PER_LONG,在64位机器体系结构中这个宏的值为64,所以该数组可以容纳64个文件对象。如果一个进程所打开的文件对象超过64个,内核将分配一个新数组,并且将fdt指针指向它。所以对适当数量的文件对象的访问会执行的很快,因为它是对静态数组进行的操作;如果一个进程打开的文件数量过多,那么内核就需要建立新数组。所以如果系统中有大量的进程都要打开超过64个文件,为了优化性能,管理员可以适当增大NR_OPEN_DEFAULT的预定义值。
和进程相关的第二个结构体是fs_struct。该结构由进程描述符的fs域指向。它包含文件系统和进程相关的信息,定义在文件<linux/fs_struct.h>中,下面是它的具体结构体和各项描述:
1 | struct fs_struct { |
该结构包含了当前进程的当前工作目录和根目录。
第三个也是最后一个相关结构体是namespace结构体。它定义在文件<linux/mmt_namespace.h>中,由进程描述符中的mmt_namespace域指向。2.4内核版本之后,单进程命名空间被加入到内核中,它使得每一个进程在系统中都看到唯一的安装文件系统—-不仅是唯一的根目录,而且是唯一的文件系统层次结构。下面是其具体结构和描述:
1 | struct mmt_namespace { |
list域是连接已安装文件系统的双向链表,它包含的元素组成了全体命名空间。
上述这些数据结构都是通过进程描述符连接起来的。对多数进程来说,它们的描述符都指向唯一的file_structs和fs_struct结构体。但是,对于那些使用克隆标志CLONE_FILES或CLONE_FS创建的进程,会共享这两个结构体。所以多个进程描述符可能指向同一个files_struct或fs_struct结构体。每个结构体都维护一个count域作为引用计数,它防止在进程正使用该结构体时,该结构被撤销。
namespace结构体的使用方法却和前两种结构体完全不同,默认情况下,所有的进程共享同样的命名空间(也就是,它们都从同样的挂载表中看到同一个文件系统层次结构)。只有在进行clone()操作时使用CLONE_NEWS标志,才会给进程一个唯一的命名空间结构体的拷贝。因为大多数进程不提供这个标志,所有进程都继承父进程的命名空间。因此,在大多数系统上只有一个命名空间,不过,CLONE_NEWS标志可以使这一功能失效。
小结
Linux支持了相当多种类的文件系统。从本地文件系统(如ext3和ext4)到网络文件系统(如NFS和Coda),Linux在标准内核中已支持的文件系统超过60种。VFS层提供给这些不同文件系统一个统一的实现框架,而且也提供了能和标准系统调用交互工作的统一接口。由于VFS层的存在,使得在Linux上实现新文件系统的工作变得简单起来,它可以轻松地使这些文件系统通过标准Unix系统调用而协同工作。
本章描述了VFS的目的,讨论了各种数据结构,包括最重要的索引节点、目录项以及超级块对象。下章将讨论数据如何从物理上存放在文件系统中。