设备与模块
《Linux内核设计与实现》第17章总结归纳
序言
- 设备类型:在所有Unix系统中为了统一普通设备的操作所采用的分类
- 模块:Linux内核中用于按需加载和卸载目标码的机制
- 内核对象:内核数据结构支持面向对象的简单操作,还支持维护父子对象之间的关系
- sysfs:表示系统中设备树的一个文件系统
设备类型
在Linux以及所有的Unix中,设备被分为三种类型;
- 块设备
通常缩写为blkdev,块设备是可寻址的,寻址以块为单位。块设备通常支持重定位操作,即对数据的随机访问。常见的块设备有硬盘,光碟,Flash。块设备通常会被挂载为文件系统。 - 字符设备
通常缩写为cdev,字符设备是不可寻址的,仅提供数据的流式访问(即一个一个字符或者一个一个字节)。常见的字符设备有键盘,鼠标,打印机等,还有大部分伪设备。应用程序可以直接访问字符设备节点与字符设备交互。 - 网络设备
一般以Ethernet Device来称呼,它提供了对网络的访问,通过一种物理适配器(如网卡)和一种特定的协议(如IP)进行的。它不是通过文件节点来访问的,而是通过套接字来这样的特殊接口来访问。 - 伪设备
并不是所有设备驱动都表示物理设备。有些设备驱动时虚拟的,仅仅提供访问访问内核功能而已,称之为伪设备。例如内核随机数发生器(/dev/null),空设备(/dev/zero),零设备(/dev/urandom),满设备(/dev/full),内存设备(/dev/mem)。
模块
Linux是单块内核的操作系统,即整个系统都运行与一个单独的保护域中,但是Linux内核却是模块化的。它允许内核在运行期间动态的向其中插入或删除代码。这些代码(相关的子例程,数据,函数出口,函数入口)被存放在一个单独的二进制镜像中,称之为模块。支持模块的好处就是基本的内核镜像能尽可能的小,因为可选的功能和驱动程序都可以以模块的形式再提供。当热插拔新设备时,可以重新载入新的驱动程序。
一个最简单模块
虽然编写“Hello World”程序属于陈词滥调,但是它就是那么合适,下面就是属于内核模块的“Hello World”。
1 | /* |
hello_init()函数是模块的入口点,它通过module_init()例程注册到系统中,在内核装载时被调用。module_init()是一个宏。
模块的所有初始化函数必须符合下面的形式。
1 | int my_init(void); |
因为它不会被外部调用,所以可以加上static修饰。在实际的模块初始化函数中,往往会注册资源,初始化硬件,分配数据结构等。如果这个文件被静态编译进入内核镜像,那么这个模块将会在内核启动时运行。hello_exit()函数是模块的出口函数,他由module_exit()例程注册到系统。在模块从内核中卸载时,便会调用hello_exit()。简单来说,该函数负责对模块生命周期内所做的一切事情的撤销工作,在hello_exit()返回后,模块就被卸载了。
退出函数必须符合下面的形式。
1 | void my_exit(void); |
与init函数一样,你也可以用static修饰它。MODULE_LISENCE()用于指定模块的版权;MODULE_AUTHOR()和MODULE_DESCRIPTION()用于指定作者和模块的简要描述,他们完全是用作信息记录目的。
构建模块
在2.6的内核中采用了“KBuild”构建系统,现在构建模块相比从前更加容易。构建过程的第一步是决定在哪里管理模块代码。你可以把模块源码加入到内核源代码树上,或者是作为一个补丁,最终把你的代码合并到正式的内核代码树上;另一种可行的方法就是在内核源代码树之外维护和构建你的模块代码。
放在内核源代码树上
当你决定了把你的模块放在内核源代码树上,下一步就要清楚放在内核源代码树的何处。设备驱动程序位于/drivers的子目录下,在其内部,设备驱动程序被进一步按照类别,类型或者特殊驱动程序等更有序的组织起来。如字符设备存放于/drivers/char目录下,块设备存放于/drivers/block目录下,USB设备存放于/drivers/usb目录下。文件的具体组织规则并不是墨守成规,不容打破,很多USB设备也属于字符设备。不管怎样,这些组织关系对我们来说相当容易理解,而且也很准确。
假定你有一个字符设备,而且你希望将它存放于/drivers/char目录下,建议建立你自己代码的子目录。你的驱动程序是一个钓鱼竿和计算机的接口,那么你需要在/drivers/char下面建立一个fishing的子目录。接下来需要向/drivers/char下的Makefile文件添加一行
1 | obj-m += fishing/ |
这行代码告诉模块构建系统,在模块编译时需要进入fishing/子目录中。更有可能发生的是,你的驱动程序的编译取决于一个特殊配置选项;比如,可能的CONFIG_FISHING_POLE。那么,你可能需要用下面的指令
1 | obj-$(CONFIG_FISHING_POLE) += fishing/ |
最后,在/drivers/char/fishing/下,添加一个新的Makefile文件,其中需要有下面这行指令
1 | obj-$(CONFIG_FISHING_POLE) += fishing.o |
以后,假如你的钓鱼竿程序需要更加智能化–它需要可以增加自动检测钓鱼线的功能。那么你的源程序就不止一个C文件了
1 | obj-$(CONFIG_FISHING_POLE) += fishing.o |
每当设置了CONFIG_FISHING_POLE,fishing-main.c和fishing-line.c就会被一起编译链接到fishin.ko中去。最后需要注意的是,构建文件时你可能需要额外的编译标记,你只需要在Makefile中添加如下命令,
1 | EXTRA_CFLAGS += -DTITANIUM_POLE |
然后就开始编译吧!
放在内核代码外
模块在内核内和在内核外的构建的区别在于构建过程。当模块在内核源码树外时,你必须告诉make如何找到内核源代码文件和Makefile文件,
1 | make -C /kernel/source/location SUBDIRS=$PWD modules |
在这个例子中,/kernel/source/location是你自己配置的内核源码树。
安装模块
编译后的模块将被装入到目录/lib/modules/version/kernel下,在将kernel/目录下的每一个目录都对应着内核源码树中的模块位置。如果使用的是2.6.34的内核,而且将你的模块源代码直接放在/drivers/char下,那么编译后的钓鱼杆驱动程序的存放路径将是:/lib/modules/2.6.34/kernel/drivers/char/fishing.ko。
下面的构建命令用来安装编译的模块到合适的目录下:
1 | make modules_install |
产生模块依赖性
Linux模块之间存在依赖性,也就是说钓鱼模块依赖于鱼饵模块,那么当你载入钓鱼模块时,鱼饵模块会自动被载入。你可以使用如下命令获取内核模块之间的依赖信息:
1 | depmod |
载入模块
载入模块最简单的方法就是通过insmod命令,它的功能就是请求内核载入指定的模块:
1 | insmod module.ko |
管理配置选项
这里我们继续以钓鱼竿驱动程序为例,看看一个新的配置选项如何加入。
由于2.6内核新引入了“Kbuild”系统,你所需要做的就是想Kconfig文件中添加一项,用以对应内核源码树。对驱动程序而言,kconfig通常和源代码处于同一目录。如果钓鱼杆驱动程序位于/drivers/char下,那么/drivers/char/kconfig也会存在。
如果你新引入了一个子目录fishing/,那么你必须在一个已经存在的kconfig文件中将它引入:
1 | source "drivers/char/fishing/kconfig" |
请看kconfig中钓鱼竿模块的选项,如下所示:
1 | config FISHING_POLE |
第一行定义了该选项所代表的配置目标,注意CONFIG_前缀并不需要带上。
第二行声明类型为tristate,也就是说可以编译进内核(Y),也可以作为模块编译(M),或者干脆不编译它(N)。如果配置选项代表的是一个系统功能,而不是一个模块,那么编译选项将用bool代替tristate,说明它不允许被编译成模块。
第三行指定默认编译选项,驱动程序一般默认不编译进入内核(N)。
help指令为该选项提供帮助文档。
除了上述选项外,还存在其他选项。比如depends指令指定了在该选项设置前,首先需要设置的选项。假设你加入
1 | depends on FISH_TANK |
到配置选项中,那么就意味着在CONFIG_FISH_TANK被选择前,我们的钓鱼竿模块是不能被使用的(Y或者M)。
select指令和depends类似,它们只有一点不同之处—那就是select指定了谁,它就会将被指定的选项强制打开,所以要慎重使用select
1 | select BAIT |
意味着当CONFIG_FISHING_POLE被激活时,配置选项CONFIG_BAIT必然被一起激活。
如果select和depends同时指定多个选项,那就需要通过&&指令来进行多选。使用的depends时,你还可以利用叹号前缀来指明禁止某个选项。比如:
1 | depends on EXAMPLE_DIRVERS && !NO_FISHING_ALLOWED |
这行指令就指定驱动程序安装要求打开CONFIG_EXAMPLE_DIRVERS选项,同时禁止CONFIG_NO_FISHING_ALLOWED选项。
tristate和bool选项往往会结合if指令一起使用,这表示某个选项取决于另一个配置选项。如果条件不满足,配置选项不但会被禁止,甚至不会显示在配置工具中。比如,要求配置系统只有在CONFIG_x86配置选项时才显示某选项。
1 | bool "x86 only" if x86 |
导出符号表
模块被载入后,就会被动态的连接到内核。注意,它与用户空间的动态链接库类似,只有被显式导出后的外部函数,才可以被动态库调用。在内核中,导出内核函数需要使用特殊的指令EXPORT_SYMBOL()和EXPORT_SYMBOL_GPL()。
导出的内核函数可以被模块调用,而未导出的函数模块则无法被调用。函数代码的链接和调用规则相比核心内核镜像的的代码而言,要更加严格。核心代码在内核中可以调用任意非静态接口,因为所有的核心源代码文件被链接成了同一个镜像。当然,被导出的符号表所含的函数必然也要是非静态的。
导出的内核符号被看作导出的内核接口,甚至被称为内核API。导出符号相当简单,在声明函数后,紧跟上EXPORT_SYMBOL()指令就搞定了。比如:
1 | /* |
如果你希望先前的函数仅对标记为GPL协议的模块可见,那么你就需要用:
1 | EXPROT_SYMBOL_GPL(get_priate_beard_color) |
如果你的代码被配置为模块,那么你就必须确保它被编译为模块时,它所用的全部接口都已经被导出,否则就会出现连接错误(而且模块不能编译成功)。
设备模型
2.6的内核增加了一个引人注目的新特性—-统一设备模型(device model)。设备模型提供了一个独立的机制专门来表示设备,并描述其在系统中的拓扑结构,从而使得系统具有以下优点:
- 代码重复最小化;
- 提供诸如引用计数这样的统一机制;
- 可以列举系统中的所有设备,观察他们的形态,并且查看他们连接的总线;
- 可以将系统中的全部设备结构以树的形式完整,有效的展示出来—-包括总线和所有的内部连接;
- 可以将设备和其对应的驱动联系起来,反之亦然;
- 可以将设备按照类型分类,比如分为输入设备,而无需理解物理设备的拓扑结构;
- 可以沿这设备树的叶子向其根节点的方向遍历,以保证能以正确的顺序关闭各个设备的电源。
内核无疑需要一棵设备树。
kobject
设备模型的核心部分就是kobject(kernel object),它由struct kobject结构体表示,定义域头文件<linux/kobject.h>中。它提供了诸如引用计数,名称,父指针等字段,可以创建对象的层次结构。具体结构如下:
1 | struct kobject{ |
name 指针指向该kobject的名称。
parent 指针指向kobject的父对象,这样一来,kobject就会在内核中构造一个对象层次结构,并且可以将多个对象间的关系表现出来。这便是sysfs的真面目:一个用户空间的文件系统,用来表示内核中kobject对象的层次结构。
sd 指针指向sysfs_dirent结构体,它在sysfs中表示的就是这个kobject。
kref 提供引用计数。ktype和kset对kobject进行描述和分类。
kobject通常是嵌入到其他结构中,其单独存在的意义不大。比如定义在<linux/cdev.h>下的struct cdev中才真正用到了kobj结构:
1 | /* |
当konject被嵌入到其他结构中时,该结构便拥有了kobject提供的标准功能。更重要的一点是,嵌入kobject的结构体可以成为对象层次架构中的一部分。比如cdev就可以通过其父指针cdev->kobj.parent 和链表 cdev->kobj.entry 插入到对象层次结构中。
ktype
kobject对象被关联到一种特殊的类型,即ktype(kernel object type)。ktype由kobj_type结构体表示,定义于头文件<linux/kobject.h>中:
1 | strcut kobj_type{ |
ktype的存在就是为了描述一族kobject的普遍特性。如此一来,不需要每一个kobject都分别定义自己的特性,而是将这些普遍的特性在ktype中一次定义,然后所有的同类“kobject”都能共享一样的特性。
release函数指针指向kobject引用计数为零时要被调用的析构函数。该函数负责释放所有kobject使用的内存和其他相关清理工作。
sysyfs_ops变量指向sysfs_ops结构体。该结构体描述了sysfs文件读写时的特性。
default_attrs指向了一个attribute结构体数组。这些结构体定义了该kobject相关的默认属性。属性描述了给定对象的特征,如果该kobject导出到sysyfs,那么这些属性都将相应的作为文件而导出,数组的最后一项必须为NULL。
kset
kset是kobject对象的集合体。可以把它看作是一个容器,可将所有相关的kobject对象,比如”全部的块设备“置于同一位置。kset和ktype最大的区别就是:具有相同ktype的kobject可以被分组到不同的kset。也就是说,在Linux内核中,只有少数一些的ktype,却有多个kset。
kobject的kset指针指向相应的kset集合。kset集合由kset结构体表示,定义于头文件<linux/kobject.h>中:
1 | struct kset{ |
在这个结构中,其中list连接该集合中所有的kobject对象,list_lock是保护这个链表对象的自旋锁,kobj指向的konject对象代表了该集合的基类。uevent_ops指向了一个结构体—用于处理集合中kobject对象的热插拔操作。uevent就是用户事件(user event)的缩写,提供了与用户空间热插拔信息进行通信的机制。
kobject、ktype、kset的相互关系
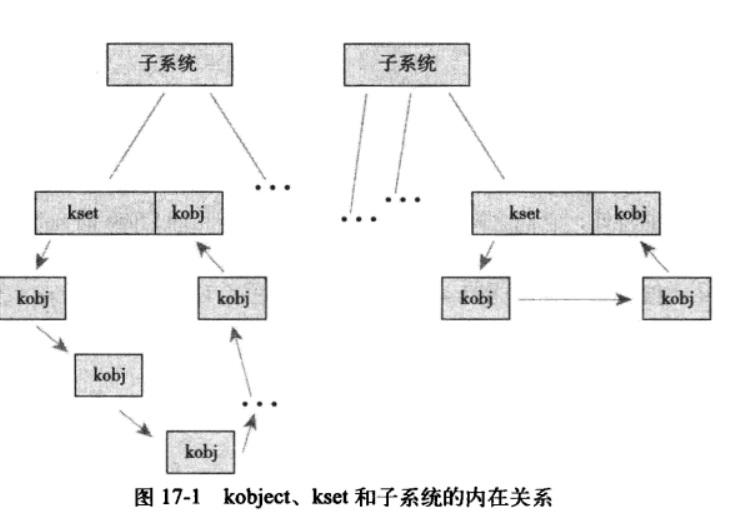
管理和操作kobject
当了解了kobject的内部基本细节后,我们来看管理和操作他的外部接口了。
使用kobject的第一步需要先进行声明和初始化。kobject通过函数kobject_init()进行初始化,该函数定义在文件<linux/kobject.h>中:
1 | void kobject_init(struct kobject *kobj,struct kobj_type *ktype); |
该函数第一个参数就是需要初始化kobject对象,在调用初始化之前,kobject必须清空:
1 | memset(kobj,0,sizeof(*kobj)); |
只有在初始化之后就可以安全的初始化parent和kset字段:
1 | struct kobject *kobj; |
or
1 | struct kobject *kobj; |
大多数情况下,应该调用kobject_create()而不是直接操作这个结构体。
引用计数
kobject的主要功能之一就是为我们提供了一个统一的引用计数系统。初始化后,koject的引用计数设置为1。只要引用计数不为零,那么该对象就会继续保留在内存中。任何包含对象引用的代码首先要增加该对象的引用计数,当代码结束后就减少它的引用计数。当引用计数跌为零时,对象便可以撤销,相关内存也都被释放。
增加和递减引用计数
增加一个引用计数可通过kobject_get()函数完成:
1 | struct kobject *kobject_get(struct kobject *kobj); |
该函数正常情况下将返回一个指向kobject的指针,如果失败则返回NULL。
减少引用计数通过kobject_put()完成,这个函数也声明在<linux/kobject.h>中:
1 | void kobject_put(struct kobject *kobj); |
如果对应的kobject的引用计数减少到零,那么与该kobject关联的ktype中的析构函数将会被调用。
kref
kobject的引用计数是通过kref结构体实现的。该结构体定义在<linux/kref.h>中:
1 | struct kref{ |
其中唯一的字段是用来存放引用计数的原子变量。那么为什么采用结构体,这是为了便于进行类型检测。在使用kref前,你必须通过kref_init()来初始化它:
1 | void kref_init(strcut kref *kref) |
这个函数简单的将原子变量置1,所以fref一旦被初始化,它所表示的引用计数便固定为1。
要获得对kref的引用,需要调用kref_get()函数,该函数增加引用计数值,没有返回值,这个函数在<linux/kref.h>中声明:
1 | void kref_get(strcut kref *kref) |
减少对kref的引用,这个函数在<linux/kref.h>中声明:
1 | void kref_put(strcut kref *kref,void (*release) (strcut kref *kref)) |
上述所有函数定义和声明分别在lib/kref.c和<linux/kref.h>中。
sysfs
sysfs文件系统是一个处于内存中的虚拟文件系统,它为我们提供了kobject对象层次结构的视图。帮助用户能以一个简单文件系统的方式来视察系统中各种设备的拓扑结构。借助属性对象,kobject可以用导出文件的方式,将内核变量提供给用户读取或者写入。
虽然设备模型的初衷是为了方便电源管理而提出的一种设备拓扑结构,但是sysfs是颇为意外的收获。为了方便调试,设备模型的开发者决定将设备结构树导出为一个文件系统。今天所有的2.6内核的系统都拥有sysfs文件系统,而且几乎都将其挂载在sys/下。
sysfs的诀窍就是吧kobject对象和目录项(directory entries)紧密联系在一起,这点是通过kobject对象中的dentry字段实现的。dentry结构体表示目录项,通过连接kobject到指定的目录项上,无疑方便的将kobject映射到该目录上。从此,把kobject导出形成文件系统就变得跟在内存中构建目录项一样简单。kobject其实已经形成了一棵树—就是我们心爱的对象体系模型。由于kobject映射到目录项,同时对象层次结构也已经在内存中形成了一棵树,因此sysfs的生成便水到渠成般的简单了。
sysfs的根目录下至少包含了十个目录:block、bus、class、dev、devices、firmware、fs、kernel、module和power。
- block下每个子目录都对应着系统中已注册的块设备。反过来,每个目录下又都包含了该块设备的所有分区。
- bus目录提供了一个系统总线试图。
- class目录包含了以高层功能逻辑组织起来的系统设备视图。
- dev目录是已注册的设备节点的视图。
- devices目录是系统中的设备拓扑结构视图,它直接映射了内核中设备结构体的组织层次。
- firmware目录包含了一些诸如ACPI、EDD、EFI等低层子系统的特殊树。
- fs目录是已注册的文件系统的视图。
- kernel目录包含内核配置项和状态信息。
- module目录则包含系统已加载模块的信息。
- power目录包含系统范围的电源去管理数据。
其中最重要的目录是devices,该目录将设备模型导出到用户空间。目录结构就是系统中的实际的设备拓扑。其他目录中的很多数据都是将devices目录下的数据加以转换加工得来的。比如,/sys/class/net/目录是以注册网络接口这一高层概念来组织设备关系的,在这个目录中可能会有目录eth0,它里面包含的devices文件其实就是一个指回到devices下实际设备目录的符号链接。
随便看看你可以访问到的任何Linux系统的sys目录,这种系统设备视图相当准确和漂亮,而且可以看到class中高层概念与devices中的低层物理设备,以及bus中的实际驱动程序之间互相联络是非常广泛的。当你认识到这种数据是开放的,换句话说,这种内核中维持系统的很好表示方式时,整个经历都是弥足珍贵的。
sysfs中添加和删除kobject
仅仅初始化kobject是不能将其导入到sysfs中去的,想要将kobject导入sysfs,你需要用到kobject_add():
1 | int kobject_add(struct kobject *kobj,struct kobject *parent,const char *fmt,...); |
kobject在sysfs的位置取决于kobject在对象层次结构中的位置。如果kobject的父指针被设置,那么在sysfs中kobject将被映射为其父目录下的子目录;如果parent没有被设置,那么kobject将被映射为kset->kobj中的子目录。如果给定的kobject中parent或kset字段都没有被设置,那么就认为kobject没有父对象,所以就会被映射成sysfs下的根级目录。这往往不是你所需要的,所以在调用kobject_add()之前,parent或者kset应该被适当的设置。sysfs中代表kobject的目录名字是由fmt指定的,它也接受printf()样式的格式化字符串。
辅助函数kobject_create_and_add()把koject_create()和kobject_add()所做的工作放在一个函数中:
1 | struct kobject *kobject_create_and_add(const char *name,struct kobject *parent); |
从sysfs中删除一个kobject对应文件目录,需要使用函数kobject_del():
1 | void kobject_del(struct kobject *kobj); |
上述函数都定义于文件lib/kobject.c中,声明位于头文件<linux/kobject.h>中。
向sysfs中添加文件
我们已经看到kobject被映射为文件目录了,而且所有的对象层次结构都优雅的,一个不少的映射成sys下的目录结构。但是里面的文件是什么,sysfs仅仅是一个漂亮的树,但是没有提供实际数据的文件。
默认属性
默认的文件集合是通过kobject和kset中的ktype提供的。因此所有具有相同类型的kobject在它们对应的sysfs目录下都拥有相同默认文件集合。kobject_type字段含有一个字段—default_attrs,它是一个attribute结构体数组。这些属性负责将内核数据映射成sysfs中的文件。
attribute结构体定义在文件<linux/sysfs.h>中:
1 | /* |
其中名称字段提供了该属性的名称,最终出现在sysfs中的文件名就是它。owner字段在存在所属模块的情况下指向其所属的module结构体。如果一个模块没有该属性,那么该字段为NULL。mode 字段类型为mode_t,它表示了sysfs中该文件的权限。对于只读属性而言,如果是所有人都可以读它,则该字段设置为S_IRUGO;如果只限于所有者可读,则该字段被设置为S_IRUSR。同样对于可写属性,可能会设置该字段为S_IRUGO | S_IWUSR。sysfs中的所有文件和目录的uid与gid标志均为0。
虽然default_attr列出了默认的属性,sysfs_ops字段则描述了如何使用他们。sysfs_ops字段指向了一个定义于文件<linux/sysfs.h>的同名的结构体:
1 | struct sysfs_ops{ |
当从用户空间读取sysfs的项时调用show()方法。它会拷贝由attr提供的属性值到buffer指定的缓冲区中,缓冲区大小为PAGE_SIZE字节;store()方法在写操作时调用,它会从buffer中读取size大小的字节,并将其存放入attr表示的属性结构体变量中。
创建新属性
内核为能在默认集合上,再添加新属性而提供了sysfs_create_file()接口:
1 | int sysfs_create_file(struct kobject *kobj,const struct attribute *attr); |
注意,kobject中的ktype所对应的sysfs_ops操作将负责处理新属性。现有的show()和store()方法必须能够处理新属性。
除了添加文件外,还有可能需要创建符号链接。再sysf中创建一个符号链接很简单:
1 | int sysyfs_create_link(struct kobject *kobj,struct kobject *target,char *name); |
该函数创建的符号链接名由name决定,连接则由kobj对应的目录映射到target指定的目录。如果成功该函数返回零,如果失败返回负的错误码。
删除新属性
删除一个属性需要通过函数sysfs_remove_file()完成:
1 | void sysfs_remove_file(struct kobject *kobj,const struct attribute *attr); |
一但调用返回,给定的属性将不再存在于给定的kobject目录中。另外由sysfs_create_link()创建的符号链接可通过函数sysfs_remove_link()删除:
1 | void sysfs_remove_link(struct kobject *kobj,char *name); |
调用一旦返回,在kobj对应目录中的名为name的符号链接将不复存在。
上述四个函数在文件<linux/kobject.h>中声明;sysfs_create_file()和sysfs_remove_file()定义于文件fs/sysfs/file.c。sysyfs_create_link()和sysfs_remove_link()定义于文件fs/sysfs/symlink.c中。
内核事件层
内核事件层实现了内核到用户的消息通知系统,就是建立在上文一直讨论的kobject基础之上。在2.6.0版本之后,显而易见,系统确实需要一种机制来帮助事件传出内核输入到用户空间,特别是对于桌面系统来说吗,因为他需要更完整和异步的系统。为此就要让内核将其事件压倒堆栈:硬盘满了,CPU过热了,分区挂载了。
早期的事件层没有采用kobject和sysfs,他们如过眼云烟,没有存在多久。现在的事件层借助kobject和sysfs实现以证明相当理想。内核事件层把事件模拟册成信号—从明确的kobject对象发出,所以每个事件源都是一个sysfs路径。如果请求的事件与你的第一个硬盘相关,那么sys/block/had便是源树。实质上,在内核中我们认为事件都是从幕后的kobject对象产生的。
每个事件都被赋予了一个动词或者动作字符串表示信号。该字符串会以“被修改过”或者“未挂载”等词语来描述事件。
最后。每个事件都有一个可选的负载(payload)。相比传递任意一个标识负载的字符串到用户空间而言,内核事件层使用sysfs属性代表负载。
从内部实现来讲,内核事件由内核空间传递到用户空间需要经过netlink。netlink是一个用于传送网络信息的多点传送套接字。使用netlink就意味着从用户空间获取内核事件就如同在套接字上堵塞一样易如反掌。方法就是用户空间实现一个系统后台服务用于监听套接字,处理任何读到的信息,并将事件传送到系统栈里面。对于这种用户后台服务来说,一个潜在的目的就是将事件融入D-BUS系统。D-BUS系统已经实现了一套系统范围的消息总线,这种总线可帮助内核如同系统中其他组件一样地发出信号。
在内核代码中向用户空间发送信号使用函数kobject_uevent():
1 | int kobject_uevent(struct kobject* kobj,enum kobject_action action); |
第一个参数指定发送该信号的对象。实际的内核事件将包含该kobject映射到sysfs的路径。
第二个参数指定了该信号的“动作”或者“动词”。实际的内核事件将包含一个映射成枚举类型kobject_action的字符串。该函数不是直接提供一个字符串,而是利用一个枚举变量来提高可重用性和保证类型安全,而且也消除了打字错误或者其他错误。该枚举变量定义于文件<linux/kobject_uevent.c>中,其形式为kOBJ_foo。当前值包含kOBJ_MOUNT、kOBJ_UNMOUNT、kOBJ_ADD、kOBJ_REOMOVE、kOBJ_CHNAGE等。这些值分别映射为字符串“mount”、“unmount”、“add”、“remove”、“change”等。当现有的这些值不够用时,允许添加新动作。
小结
本章中涉及到的内核功能有设备驱动的实现、设备树的管理、包括模块、kobject、kset、ktype和sysfs。这些功能对于设备驱动程序的开发者来说是至关重要的。因为它能让我们写出更加模块化、更为高级的驱动程序。